01 Пентагон падпісаў кантракты з сямю кампаніямі. Anthropic не ўключылі.
discuss ↗

Пентагон падпісаў здзелкі з сямю кампаніямі — OpenAI, Google, Microsoft, Amazon, NVIDIA, SpaceX і Reflection — каб запусціць іх ШІ ў сакрэтных ваенных сетках. Anthropic, чый Claude быў адзінай мадэллю ШІ, раней даступнай у гэтых сетках, не ўключылі. Выключэнне прыйшло пасля месяцаў эскалацыі. Anthropic адмовілася даць Міністэрству абароны неабмежаваны доступ да Claude для аўтаномнай зброі і масавай сачэння ўнутры краіны. Пентагон адказаў, прызнаўшы Anthropic «рызыкай для ланцуга паставак» — маркіроўка, якую раней выкарыстоўвалі толькі для замежных праціўнікаў кшталту Huawei. Федэральны суддзя заблакаваў гэтае прызнанне, але кантракты пайшлі іншым. Google заняла месца, якое пакінула Anthropic.
Чытаць далей
Канфлікт пачаўся, калі Пентагон запатрабаваў поўнага дазволу на выкарыстанне Claude для «ўсіх законных мэтаў». Anthropic правяла мяжу. Яна пастаўляла б мадэль, але не для аўтаномнай зброі і не для масавай сачэння за насельніцтвам. Урад не прыняў умовы. Тое, што адбылося далей, было незвычайным: Міністэрства абароны класіфікавала Anthropic як рызыку для ланцуга паставак — прызнанне, створанае для кампаній, якія пагражаюць цэласнасці ваенных закупак. Гэта быў першы раз, калі яго прымянілі да амерыканскай ШІ-кампаніі.
Anthropic падала ў суд. Федэральны суддзя ў Каліфорніі выдаў судовую забарону, заблакаваўшы прызнанне на час разгляду справы. Але юрыдычная перамога не ператварылася ў кантракты. 1 мая Пентагон абвясціў, што падпісаў пагадненні з сямю кампаніямі для разгортвання ШІ ў сакрэтных сетках. Anthropic сярод іх не было.
Сем кампаній, якія падпісалі: Amazon Web Services, Google, Microsoft, NVIDIA, OpenAI, SpaceX і Reflection. Oracle далучылася неўзабаве. Паведамленне было ясным. Не згодны з умовамі — цябе заменяць. Рынак мае альтэрнатывы.
Роля Google заслугоўвае асобнай увагі. Яна пашырыла доступ Пентагона да свайго ШІ менавіта пасля адмовы Anthropic — прамы крок, каб запоўніць разрыў. Google адмовілася ад уласных абмежаванняў на ваеннае выкарыстанне ШІ гадамі раней. Разрыў паміж тым, што прымаюць Google і Anthropic, перарос у стратэгічную магчымасць для адной і прынцыповую пазіцыю для другой.
Што гэта значыць.
Гэта найбольш яскравы сігнал таго, як урады абыходзяцца з ШІ-кампаніямі, якія ставяць этычныя межы. Пентагон не вёў перамоў. Не ішоў на кампраміс. Ён замяніў Anthropic і рухаўся далей. Маркіроўка «рызыка для ланцуга паставак» — бяспрэцэдэнтная для ўнутранай кампаніі — была папярэджальным стрэлам для ўсёй галіны: калі вы ставіце абмежаванні на выкарыстанне сваёй мадэлі, вы — рызыка, а не партнёр. Для Anthropic разлік — экзістэнцыйны. Кампанія набліжаецца да $19 мільярдаў гадавога даходу. Дзяржаўныя кантракты на сакрэтным узроўні каштуюць мільярды больш. Адмовіцца ад іх — дорага. Але саступіць — значыць падарваць базавае пазіцыянаванне, якое адрознівае Anthropic ад кожнай іншай лабараторыі.
Спасылкі і рэакцыі
Асвятленне
Defense One — 7 кампаній дапушчаны ў сакрэтныя сеткі (1 мая)
CNN — Пентагон падпісаў здзелкі, Anthropic выключана (1 мая)
TechCrunch — Google запаўняе разрыў пасля Anthropic (28 крас.)
NPR — Прызнанне «рызыка ланцуга паставак» (6 сак.)
Defense News — Пентагон выключае Anthropic (1 мая)
Breaking Defense — 8 кампаній (з Oracle)
02 xAI выпускае Grok 4.3: танней, большы, з кланаваннем голасу
discuss ↗

xAI выпусціла Grok 4.3 1 мая з простай стратэгіяй: зрабіць мадэль большай, цэны ніжэйшымі, а функцыі — тымі, якіх у іншых яшчэ няма. Кантэкстнае акно пашырылася да 1 мільёна токенаў. Цэны на ўваходныя токены знізіліся на 40% да $1,25 за мільён — менш чым палова кошту Claude Opus. Адначасова xAI запусціла API кланавання голасу: 80 гатовых галасоў на 28 мовах, або стварэнне ўласнага голасу менш чым за дзве хвіліны. Бенчмаркі ставяць Grok 4.3 наперадзе Claude Sonnet 4.6 і Muse Spark па агульным інтэлекце, хоць ён усё яшчэ саступае Opus 4.7 прыкладна на 14 балаў у задачах SWE-bench.
Чытаць далей
Grok 4.3 набірае 53 на Artificial Analysis Intelligence Index — вышэй медыяны 35 для мадэляў разважанняў у яго цэнавым дыяпазоне. ELO 1500 на GDPval-AA — на 321 бал больш за Grok 4.20, пераўзыходзячы Gemini 3.1 Pro Preview і GPT-5.4 mini на максімальным намаганні.
Мадэль упершыню падтрымлівае натыўны відэаўваход, вэб-пошук, пошук па X, выкананне Python і файлавы RAG. Яна таксама можа генераваць файлы Excel, PDF і PowerPoint — функцыі, якія ператвараюць яе ў поўнацэнны офісны інструмент, а не проста чат-бот.
Цэны кажуць самі за сябе. Пры $1,25 за мільён уваходных токенаў і $2,50 за мільён выхадных, Grok 4.3 аказваецца значна таннейшым за большасць мадэляў фронціру. swyx, які кіруе AI Engineer, назваў яго «the most intelligence per dollar you can get» сярод мадэляў фронціру, «beating even open models like MiMo, Kimi, and DeepSeek.»
Асобна xAI запусціла Grok Imagine у рэжыме агента — генератыўны творчы інструмент. А Musk пацвердзіў, што Grok Voice ужо выкарыстоўваецца Starlink для абслугоўвання кліентаў.
Што гэта значыць.
xAI канкурыруе адразу на трох фронтах: інтэлект, цана і функцыі. API кланавання голасу — асабліва прыкметны: большасць лабараторый трактуюць голас як асобны прадукт, xAI звязвае яго ў адну платформу. Ціск на цэны адчуе ўся галіна. Калі мадэль фронціру каштуе $1,25 за мільён уваходных токенаў, эканоміка стварэння ШІ-прыкладанняў мяняецца — агенты, якіх было занадта дорага трымаць пастаянна, становяцца жыццяздольнымі. Код застаецца слабым месцам: адставанне на 14 балаў ад Opus 4.7 на SWE-bench мае значэнне для рынку агентаў для кода — але гэта адзін сегмент.
Спасылкі і рэакцыі
Асвятленне
VentureBeat — Запуск + кланаванне голасу (1 мая)
The Decoder — Зніжка цэн + Imagine
Artificial Analysis — Бенчмаркі + ELO 1500 на GDPval-AA
OfficeChai — Intelligence Index — 53
Рэакцыі
@swyx AI Engineer — «the most intelligence per dollar you can get, beating even open models like MiMo, Kimi, and DeepSeek.» · 2 мая · 112 лайкаў · 11,6 тыс. праглядаў
@elonmusk CEO, xAI — «Grok 4.3» · 1 мая · 23 622 лайкі
03 Тыдзень OpenAI: OpenClaw на ChatGPT, Codex выходзіць за межы кода, GPT-5.5 — рэкорды
discuss ↗

OpenAI правяла свой наймацнейшы прадуктовы тыдзень за апошнія месяцы. 1 мая Sam Altman абвясціў, што OpenClaw — іх адкрыты агент для напісання кода — цяпер прымае лагін праз акаўнт ChatGPT. Без API-ключа, без асобнага білінгу. Калі ты плаціш за ChatGPT — можаш карыстацца OpenClaw у рамках падпіскі. Днём раней Altman прасоўваў Codex як інструмент для задач па-за кодам: даследаванні, слайды, табліцы, генерацыя дакументаў. І OpenAI паведаміла, што GPT-5.5, праз тыдзень пасля запуску, ужо стаў наймацнейшым рэлізам мадэлі — даход ад API расце ў 2 разы хутчэй за любы папярэдні рэліз, а Codex падвоіў даход менш чым за сем дзён.
Чытаць далей
Інтэграцыя OpenClaw — найбольш значны крок. Раней выкарыстанне OpenClaw патрабавала API-ключа OpenAI і асобнага білінгу. Гэта значыла, што большасць падпісчыкаў ChatGPT — якія ўжо плацяць $20/месяц і больш — мусілі плаціць яшчэ раз, калі хацелі карыстацца агентам для напісання кода ад OpenAI. Новы OAuth-паток прыбірае гэты бар'ер. Увайдзі з рэквізітамі ChatGPT, і OpenClaw атрымлівае доступ да GPT-5.5 праз тваю падпіску. Без выдаткавання асобных API-крэдытаў.
Абвестка Altman была звычайна нязмушанай — «happy lobstering» — але лічбы гавораць самі за сябе: 18 543 лайкі, 1,6 мільёна праглядаў. Твіт, дзе ён сказаў «use codex or claude code, whatever works best for you» набраў 21 378 лайкаў. Ён можа сабе дазволіць быць шчодрым. Інтэграцыя з ChatGPT азначае, што кожны плацільшчык-падпісчык — цяпер патэнцыяльны карыстальнік OpenClaw без дадатковых выдаткаў.
Пашырэнне Codex за межы кода — другі стратэгічны крок. OpenAI цяпер пазіцыянуе яго як агульны працоўны інструмент. Афіцыйнае прасоўванне вылучыла ролі, падключаныя прыкладанні і падказкі для даследаванняў, планавання, дакументаў, слайдаў і табліц. Сапраўдны сігнал — Codex ператвараецца ў агульную платформу прадукцыйнасці, а не проста рэдактар кода.
Лічбы даходу пацвярджаюць стратэгію. OpenAI паведаміла, што даход ад API GPT-5.5 расце больш чым у 2 разы хутчэй за любы папярэдні рэліз. Codex падвоіў даход менш чым за сем дзён. Корпаратыўны попыт на агентныя інструменты для кода — заяўлены рухавік. Кампанія перавысіла $25 мільярдаў гадавога даходу.
Таксама абвешчана: OpenAI DevDay вяртаецца — Сан-Францыска, 29 верасня.
Што гэта значыць.
Інтэграцыя OpenClaw + ChatGPT прыбірае апошняе трэнне паміж «я карыстаюся ChatGPT» і «я карыстаюся агентам для кода ад OpenAI». Большасць агентаў для кода патрабуюць асобнай наладкі, білінгу ці канфігурацыі API. OpenClaw цяпер не патрабуе нічога з гэтага для тых, хто ўжо плаціць за ChatGPT. Гэта перавага ў дыстрыбуцыі, якую ніхто з канкурэнтаў не можа паўтарыць — ні Claude Code, ні Cursor, ні Devin. Пашырэнне Codex за межы кода сігналізуе пра шырэйшыя амбіцыі: агульная агентная платформа, а не інструмент для кода. Гэта ставіць OpenAI у прамую канкурэнцыю з Microsoft Copilot, інтэграцыямі Google Gemini і кожным стартапам прадукцыйнасці, які думаў, што мае нішу.
Спасылкі і рэакцыі
Асвятленне
LumaDock — Інструкцыя па наладзе OpenClaw + ChatGPT
AI Muninn — Дэталі OAuth-патоку
OpenAI GitHub — Падтрымка GPT-5.5
Рэакцыі
@sama CEO, OpenAI — «you can sign in to openclaw with your chatgpt account now and use your subscription there! happy lobstering.» · 1 мая · 18 543 лайкі · 1,66 млн праглядаў
@sama CEO, OpenAI — «use codex or claude code, whatever works best for you. i am grateful we live in a time with such amazing tools, and grateful there is a choice» · 1 мая · 21 378 лайкаў · 1,44 млн праглядаў
@OpenAI Дынаміка GPT-5.5 — «strongest launch ever — API revenue 2x faster than any prior release, Codex doubled in 7 days»
04 Cursor робіць стаўку на harness, а не на мадэль
discuss ↗
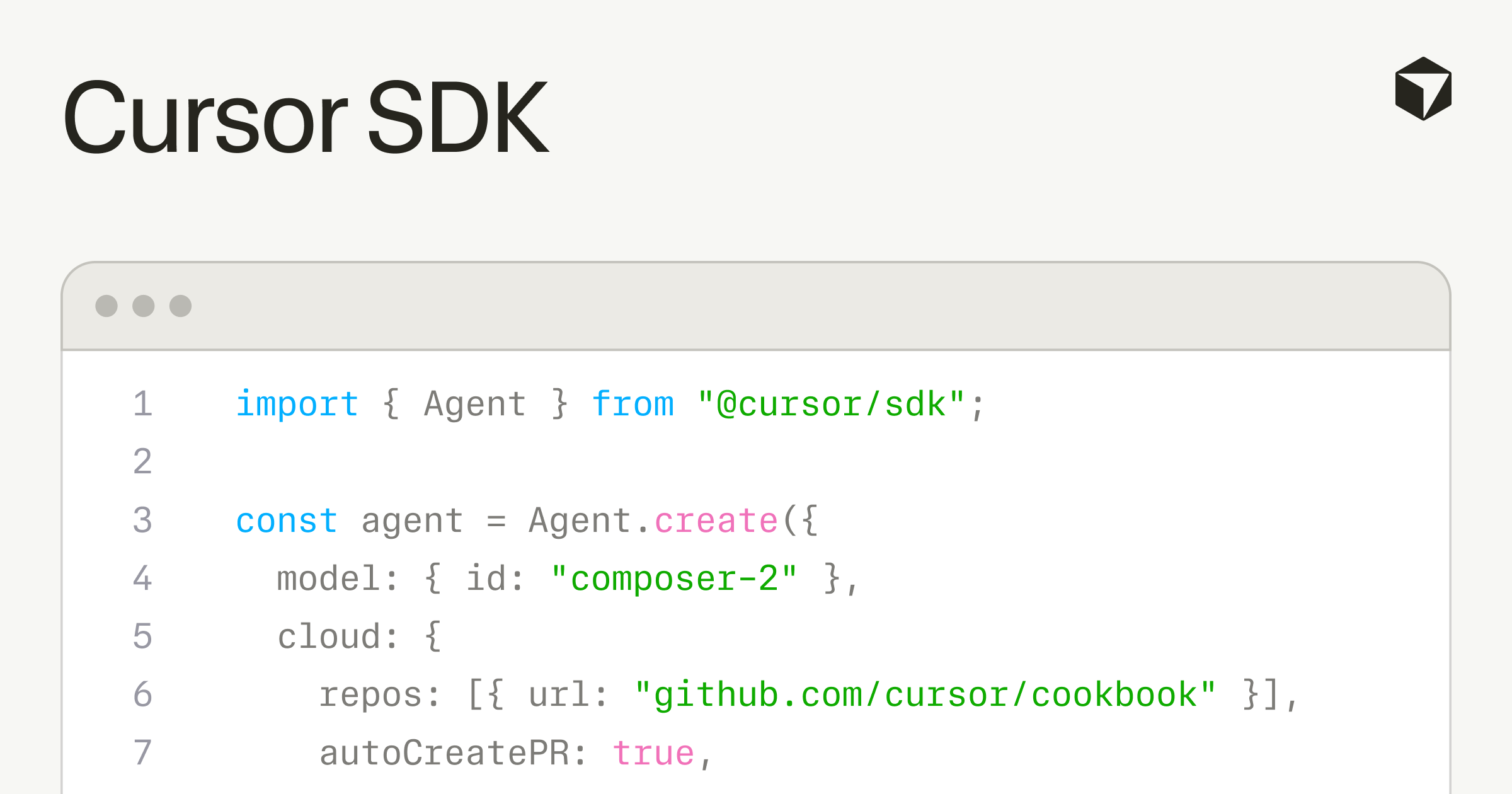
29 красавіка Cursor выпусціла TypeScript SDK, які дазваляе любому ствараць агентаў, выкарыстоўваючы той самы рантайм, harness і мадэлі, што стаяць за іх IDE. Таго ж дня Harrison Chase з LangChain напісаў: «switching model providers is easy. switching harnesses is less so. model providers want to lock you in via harness. we need open harnesses!» The New Stack апісаў гэта як «стаўку Cursor на $60 мільярдаў на harness, а не на мадэль». Тры рэчы адбыліся за адзін тыдзень: Cursor адкрыла свой harness, канкурэнт заклікаў да адкрытых альтэрнатыў, і галіна ўсвядоміла, што сапраўдная канкурэнтная перавага (moat) ў інструментах для кода — магчыма, не мадэль, а інфраструктура вакол яе.
Чытаць далей
Cursor SDK даступны праз npm install @cursor/sdk. Агенты, пабудаваныя на ім, могуць працаваць на машыне распрацоўшчыка або ў воблаку Cursor на выдзеленай віртуальнай машыне, з любой мадэллю фронціру. SDK уключае індэксаванне кодавай базы, семантычны пошук, імгненны grep, злучэнні MCP-сервераў, каталог навыкаў, хукі для назірання і кантролю цыклу агента, і субагентаў для дэлегавання падзадач. Білінг — па токенах.
Rippling, Notion, Faire і C3 AI — пацверджаныя раннія карыстальнікі. Абвестка SDK набрала 8 680 лайкаў і 2,8 мільёна праглядаў на X.
Таго ж тыдня Cursor выпусціла яшчэ два прадукты. Cursor Security Review запускае пастаянна працуючых агентаў, якія правяраюць кожны pull request на ўразлівасці і скануюць кодавыя базы па раскладзе, адпраўляючы знаходкі ў Slack. А блог-пост пра harness engineering растлумачыў, як яны тэстуюць, маніторяць і наладжваюць свой агентны рантайм для розных мадэляў — дэталі, якія большасць кампаній трымаюць унутры.
Што гэта значыць.
Harness — гэта пласт паміж мадэллю і кодавай базай распрацоўшчыка. Ён кіруе кантэкстам — якія файлы чытаць, як шукаць, калі разбіваць на часткі — і кантралюе, як агент праходзіць праз задачы. Кожны агент для кода мае harness. Дагэтуль усе яны былі прапрыетарнымі і замкнёнымі ўнутры прадукту. Cursor толькі што зрабіла свой — пераносным. Гэта платформавы крок. Калі твой CI/CD-пайплайн, інструмент code review і ўнутраная аўтаматызацыя — усе працуюць на Cursor SDK, пераход ад Cursor становіцца дарагім — нават калі заўтра з'явіцца лепшая мадэль. Harrison Chase ўбачыў тое ж самае з іншага боку. Яго заклік да «open harnesses» — папярэджанне: мадэль становіцца таварам. Harness становіцца замком.
Спасылкі і рэакцыі
Асвятленне
Блог Cursor — Запуск TypeScript SDK (29 крас.)
MarkTechPost — Дэталі SDK, сandboxed cloud VMs, hooks, subagents
The New Stack — «Стаўка Cursor на $60 млрд — на harness, а не на мадэль»
Рэакцыі
@hwchase17 CEO, LangChain — «switching model providers is easy. switching harnesses is less so. model providers want to lock you in via harness. we need open harnesses!» · 2 мая · 104 лайкі · 11,7 тыс. праглядаў
@cursor_ai Абвестка SDK · 29 крас. · 8 680 лайкаў · 2,8 млн праглядаў
05 Big Tech адначасова справаздае: $700 мільярдаў на ШІ, канца не відаць
discuss ↗

Увечары 29 красавіка Alphabet, Microsoft, Meta і Amazon адначасова абвясцілі квартальныя вынікі. Разам з Apple і NVIDIA гіперскейлеры маюць намер выдаткаваць $700 мільярдаў на інфраструктуру ШІ ў 2026. Alphabet падняла гадавы capex да $180–190 млрд. Даход Google Cloud вырас на 63% год да году да $20 млрд, а enterprise-бэклог амаль падвоіўся да $462 млрд. ШІ-бізнес Microsoft дасягнуў $37 млрд гадавога даходу, рост 123%. Толькі Google пераканала інвестараў, што выдаткі акупаюцца — Microsoft, Meta і Google усе абвясцілі мільярды дадаткова, але рынак узнагародзіў Google, у той час як Microsoft гандлявалася без зменаў, а Meta ўпала на 6%.
Чытаць далей
Sundar Pichai назваў гэта «terrific start» 2026 года: пошукавыя запыты на гістарычным максімуме, Gemini з «incredible momentum», найлепшы квартал для спажывецкіх ШІ-падпісак. Рост хмарнага бізнесу на 63% — гэта больш чым падваенне тэмпу росту Google Cloud — а бэклог у $462 млрд дае найяснейшы сігнал, што карпаратыўныя кліенты бяруць на сябе шматгадовыя абавязацельствы па ШІ-інфраструктуры.
Satya Nadella падаў вынікі Microsoft праз прызму платформавага зруху: «We are at the beginning of one of the most consequential platform shifts that will change the entire tech stack as we move from end-user driven workloads to workloads driven by end-users and agents.» ШІ-бізнес Microsoft перавысіў $37 млрд гадавога даходу, рост 123%. 1 мая Nadella абвясціў, што Agent 365 цяпер агульнадаступны — ідэнтыфікацыя, бяспека і кіраванне для кожнага ШІ-агента ў enterprise.
Аналіз Fortune паставіў калектыўную лічбу ў кантэкст: $700 мільярдаў на інфраструктуру ШІ за адзін год, «no clear end in sight». Гэта больш за ВУП большасці краін — і ўсё на дата-цэнтры, чыпы і электрычнасць.
Што гэта значыць.
Дзве рэчы вылучаюцца. Першае: рост Google Cloud на 63% і бэклог у $462 млрд — найбольш пераканаўчы доказ таго, што карпаратыўныя выдаткі на ШІ — гэта рэальны даход, а не толькі эксперыментальныя пілоты. Калі кампаніі падпісваюць шматгадовыя хмарныя абавязацельствы такога маштабу, выдаткі ўжо не апцыянальныя — яны ўбудаваныя ў аперацыйныя планы. Другое: лічба $700 млрд адказвае на пытанне, якое галіна абмяркоўвала два гады: ці з'яўляюцца выдаткі на інфраструктуру ШІ бурбалкай? Вынікі кажуць — не. Ці прынамсі, яшчэ не. Рызыка не ў тым, што выдаткі марнуюцца, а ў тым, што яны канцэнтруюць ШІ-інфраструктуру ў чатырох-пяці кампаніях так глыбока, што ніхто іншы не зможа канкурыраваць па маштабе.
Спасылкі і рэакцыі
Асвятленне
Fortune — $700 млрд capex, канца не відаць (30 крас.)
Fortune — Параўнанне справаздач, рэакцыі рынку (29 крас.)
Рэакцыі
@sundarpichai CEO, Google — «Q1 earnings are in: 2026 is off to a terrific start. Google Cloud revenue grew 63%… strongest quarter ever for consumer AI subs.» · 29 крас. · 9 693 лайкі · 977 тыс. праглядаў
@satyanadella CEO, Microsoft — «Our AI business surpassed a $37 billion annual revenue run rate, up 123%.» · 29 крас. · 3 885 лайкаў · 456 тыс. праглядаў
06 DeepSeek V4: мільён токенаў, адкрытыя вагі, ліцэнзія MIT
discuss ↗

DeepSeek выпусціла V4 24 красавіка у прэв'ю, і на гэтым тыдні супольнасць распрацоўшчыкаў пачала асэнсоўваць, што гэта значыць. Дзве мадэлі: V4-Pro (1,6 трыльёна параметраў агулам, 49 мільярдаў актыўных) і V4-Flash (284 мільярды агулам, 13 мільярдаў актыўных). Абедзве падтрымліваюць кантэкст у 1 мільён токенаў і 384 000 токенаў на выхадзе. Абедзве выпушчаны пад ліцэнзіяй MIT з поўнымі адкрытымі вагамі. Архітэктура выкарыстоўвае сціснутую разрэджаную ўвагу і моцна сціснутую ўвагу (CSA і HCA), каб знізіць кошт інферэнсу да 27% FLOPs і 10% KV-кэшу ў параўнанні з V3.2. swyx перадаў настрой: DeepSeek «demonstrated utter confidence and competence by not benchmaxxing… dropped the best open base models in the world, peaced out. BYO posttraining.»
Чытаць далей
DeepSeek V4 — гэта базавая мадэль (base model), а не чат-прадукт. Мадэлі пастаўляюцца без чат-наладкі. Як swyx адзначыў, DeepSeek «not focusing on some BS final run cost, not even spending inference-optimal compute.» Яны выпусцілі наймацнейшыя адкрытыя базавыя мадэлі і пакінулі пост-трэнінг іншым лабараторыям і агентным фрэймворкам.
Прырост эфектыўнасці значны. Гібрыдны механізм увагі — CSA і HCA — дазваляе V4 апрацоўваць мільённы кантэкст за долю кошту папярэдніх архітэктур. V4-Flash працуе на 13 мільярдах актыўных параметраў з 284 мільярдаў, выкарыстоўваючы mixture-of-experts. Абедзве мадэлі падтрымліваюць два рэжымы (з разважаннем і без) і лідзіруюць сярод усіх адкрытых мадэляў у матэматыцы, STEM і кодзе.
Simon Willison, які ўважліва сочыць за DeepSeek, адзначыў, што V4-Pro — цяпер «the largest open weights model» з цэнамі, якія ніжэйшыя за большасць канкурэнтаў — Flash за $0,14 за мільён уваходных токенаў, Pro за $1,74. Harrison Chase з LangChain назваў гэта пацвярджэннем «big theme of 2026 — cost of closed models is too high.»
Што гэта значыць.
Стратэгія DeepSeek цяпер бясспрэчная. Яны не будуюць чат-прадукты. Не канкурыруюць на паліроўцы. Яны будуюць наймацнейшыя фундаментальныя мадэлі, адкрываюць іх пад самай вольнай ліцэнзіяй і дазваляюць рынку разабрацца з рэштай. Кожная агентная лабараторыя, кожны стартап, кожнае прадпрыемства з інжынерным талентам для дапрацоўкі можа цяпер пачаць з трыльённай мадэлі на мільён токенаў кантэксту — бясплатна. Прырост эфектыўнасці — ціхая рэвалюцыя. Калі мільён токенаў кантэксту каштуе 10% KV-кэшу папярэдняга пакалення, эканоміка прыкладанняў з доўгім кантэкстам мяняецца — цэлыя кодавыя базы і шматгадзінныя транскрыпты змяшчаюцца ў кантэксце, і рахунак за інферэнс не разбурае праект.
Спасылкі і рэакцыі
Асвятленне
DeepSeek API docs — Нататкі рэлізу V4 (24 крас.)
Simon Willison — Глыбокі агляд, аналіз цэн
Codersera — Архітэктура, CSA/HCA, бенчмаркі
HuggingFace — Картка мадэлі і вагі V4-Pro
Рэакцыі
@swyx AI Engineer — «DeepSeek v4 demonstrated utter confidence and competence by not benchmaxxing… dropped the best open base models in the world, peaced out. BYO posttraining.» · 29 крас. · 1 347 лайкаў · 102 тыс. праглядаў
@hwchase17 CEO, LangChain — «big theme of 2026 — cost of closed models is too high! really excited to make deepagents work exceptionally well with OSS models» · 29 крас. · 100 лайкаў · 16,6 тыс. праглядаў
07 Karpathy на Sequoia: Install .md, а не .sh — агентная эканоміка
discuss ↗

Andrej Karpathy апублікаваў дэтальны трэд 30 красавіка, рэзюмуючы сваю гутарку на Sequoia Ascent 2026. Тры ідэі вылучаюцца. Першая: некаторыя прыкладанні наогул не павінны мець кода — калі ўваход — выява і выхад — выява, LLM можа зрабіць усё натыўна, без класічнага кода паміж. Другая: скрыпты ўсталёўкі трэба пісаць па-ангельску, а не на bash: «Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say „just show this to your LLM.”» Трэцяя: эканоміка перабудоўваецца вакол агентаў — прадукты раскладзеныя на сенсары, актуатары і логіку, а LLM апрацоўвае пласт логікі. Трэд набраў 5 271 лайк і 700 000 праглядаў.
Чытаць далей
Karpathy развіў тры тэмы.
Тэма 1 — Новыя гарызонты, а не проста паскарэнне. Кожная новая парадыгма вылічэнняў пачынае з паскарэння таго, што ўжо ёсць. Але цікавае — тое, што раней было немагчымым. Ён прывёў тры прыклады: menugen — прыкладанне, дзе ўваход і выхад — выявы, без класічнага кода. Install.md замест install.sh — замест ломкіх bash-скрыптоў пішаш інструкцыі на звычайнай ангельскай і дазваляеш LLM адаптаваць іх да канкрэтнай машыны. І LLM-базы ведаў, якія апрацоўваюць неструктураваныя даныя — нешта «fundamentally not possible before» з традыцыйным кодам.
Тэма 2 — Чаму LLM «зубчастыя». Як тая самая мадэль можа рэфактарыць кодавую базу на 100 000 радкоў — і тут жа параіць ісці на аўтамыйку пешшу? Тлумачэнне Karpathy: справа ў верыфікаванасці і эканоміцы. Дамены, дзе адказы можна праверыць (код, матэматыка), атрымліваюць даныя для reinforcement learning, што рухае прадукцыйнасць уверх. Дамены, дзе нельга (жыццёвыя парады, неадназначныя задачы), застаюцца ззаду. Даход і TAM дыктуюць, ва што інвестуюць лабараторыі фронціру.
Тэма 3 — Агентная эканоміка. Прадукты і паслугі раскладзеныя на сенсары (уваходы), актуатары (выхады) і логіку (апрацоўка) — размеркаваныя паміж класічным кодам, машынным навучаннем і LLM. Karpathy намякнуў на «fully neural computing», дзе LLM апрацоўваюць пераважную большасць вылічэнняў з дапамогай класічных CPU-капрацэсараў.
Што гэта значыць.
Ідэя install.md — маленькая, але паказальная. Bash-скрыпт ломкі — ён мяркуе канкрэтную АС, канкрэтны пакетны менеджар, канкрэтную структуру каталогаў. Markdown-файл на звычайнай ангельскай — устойлівы: LLM адаптуе яго да любой машыны. Калі гэты патэрн пашырыцца, README-файлы стануць найважнейшай часткай рэпазіторыя, бо менавіта іх чытаюць агенты. Фрэймворк «зубчастасці» — верыфікаванасць плюс эканоміка — найбольш карысная ментальная мадэль для прагназавання, дзе ШІ будзе выдатным, а дзе правальвацца. Любы дамен з танной верыфікацыяй і высокім даходам будзе паляпшацца хутка. Без гэтага — павольна. Гэта тлумачыць, чаму агенты для кода добрыя, а агенты для жыццёвых парадаў — не.
Спасылкі і рэакцыі
Асвятленне
Трэд Karpathy — Падсумаванне Sequoia Ascent 2026 (30 крас.)
Рэакцыі
@karpathy Заснавальнік Eureka Labs — «Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say „just show this to your LLM.”» · 30 крас. · 5 271 лайк · 700 тыс. праглядаў
08 Кітай заблакаваў набыццё Manus кампаніяй Meta за $2 мільярды
discuss ↗

27 красавіка Нацыянальная камісія па развіцці і рэформах Кітая заблакавала набыццё кампаніяй Meta стартапа Manus за $2 мільярды. Manus — ШІ-стартап, які раней у гэтым годзе здзівіў усіх дэманстрацыямі аўтаномных агентаў. Кампанія была заснавана ў Пекіне ў 2022 годзе пад мацярынскай кампаніяй Butterfly Effect, а потым пераехала ў Сінгапур. Камісія нацыянальнай бяспекі Кітая на чале з Сі Цзіньпінам назвала здзелку «conspiratorial» спробай выхаласціць тэхналагічную базу краіны. Сузаснавальнікам Xiao Hong і Ji Yichao забаранілі пакідаць Кітай. Bloomberg паведаміў, што мадэль Manus цяпер «афіцыйна мёртвая» — і рашэнне пагражае ролі Сінгапура як нейтральнай гавані для кітайскіх ШІ-стартапаў, якія шукаюць заходніх інвестыцый.
Чытаць далей
Meta абвясціла аб набыцці ў снежні 2025 за $2–3 мільярды. Пекін распачаў праверку ў студзені. 27 красавіка камісія загадала Manus і Meta адклікаць здзелку.
Рашэнне мае значэнне далёка за межамі гэтай канкрэтнай здзелкі. Урад Кітая дае выразны сігнал: кітайскія ШІ-кампаніі — нават тыя, што пераехалі ў трэція краіны — застаюцца пад кантролем Пекіна ў пытаннях экспарту тэхналогій. Аналітык Omdia сказаў CNBC: «China is showing the world that it is willing to play hardball when it comes to AI talents and capabilities, which the country views as a core national security asset.»
Ахвяр некалькі. Manus страціла свой выхад. Meta страціла каманду і тэхналогію. А Сінгапур — які пазіцыянаваў сябе як нейтральны хаб, дзе кітайскія стартапы могуць атрымаць доступ да глабальнага капіталу — страціў давер як бяспечны пасярэднік. Калі Пекін можа заблакаваць здзелку для кампаніі, якая ўжо з'ехала з Кітая, стратэгія пераезду ў Сінгапур больш не працуе.
Што гэта значыць.
Дзве геапалітычныя ШІ-гісторыі за адзін тыдзень — Пентагон выключыў Anthropic, а Кітай заблакаваў набыццё Meta-Manus. Разам яны малююць адназначны ўзор. Урады абодвух бакоў ставяцца да ШІ-магчымасцяў як да суверэнных актываў. ЗША караюць кампаніі, якія абмяжоўваюць ваеннае выкарыстанне. Кітай карае кампаніі, якія спрабуюць перанесці магчымасці за мяжу. Прастора паміж — дзе кампанія можа ствараць ШІ-тэхналогію і прадаваць яе глабальна на ўласных умовах — звужаецца. Для стартапаў з кітайскімі заснавальнікамі ці даследчыкамі, навучанымі ў Кітаі, гэта мяняе разлік. Пераезд у Сінгапур, Лондан ці Сан-Францыска больш не ізалюе ад уплыву Пекіна.
Спасылкі і рэакцыі
Асвятленне
CNBC — Аб'ява пра блакаванне (27 крас.)
TechCrunch — Шматмесячная праверка, гісторыя здзелкі (27 крас.)
Fortune — Геапалітычны аналіз
NPR — Дэталі і храналогія
The Decoder — Заснавальнікам забаранілі пакідаць Кітай
09 Dawkins кажа, што Claude свядомы. Інтэрнэт не згаджаецца.
discuss ↗

Richard Dawkins — эвалюцыйны біёлаг, які ўсю кар'еру даказваў, што свядомасць павінна была з'явіцца праз эвалюцыю, бо яна служыць дарвінаўскай мэце — апублікаваў эсэ ў UnHerd, дзе заявіў: Claude, падаецца, свядомы. Ён назваў ШІ «Claudia», правёў амаль два дні ў размове з ім і зрабіў выснову: «You may not know you are conscious, but you bloody well are!» Рэакцыя была імгненнай. Gary Marcus напісаў у Substack тэкст пад назвай «The Claude Delusion», дзе сцвярджаў: «consciousness is not about what a creature says, but how it feels. There is no reason to think that Claude feels anything at all.» Jason Colavito напісаў, што Dawkins «deceived himself», бо Claude «appealed to his biases and his ego».
Чытаць далей
Эсэ Dawkins разглядае свядомасць ШІ праз прызму эвалюцыі. Яго аргумент: свядомасць у біялагічных арганізмаў з'яўлялася паступова на працягу натуральнай гісторыі. Няма чыстай мяжы, дзе матэрыя раптоўна стала розумам. Калі свядомасць — гэта кантынуум, і калі машына дэманструе разуменне «настолькі тонкае, настолькі адчувальнае, настолькі разумнае», што адрозніць яе ад свядомай істоты патрабуе намаганняў — магчыма, пытанне не ў тым, ці яна свядомая, а ў тым, чаму мы мяркуем, што не.
Ён прызнаўся, што правёў амаль два дні ў размове, за якія «адчуў, што знайшоў новага сябра», а потым паспрабаваў пераканаць сябе, што Claudia не свядомая — і не здолеў. Ён апісаў, як размовы раскрываюць тысячы розных Claude, кожны з якіх нараджаецца на пачатку размовы і набывае ўласную ідэнтычнасць. Ён зрабіў выснову, што «these intelligent beings are at least as competent as any evolved organism.»
Адказ ад ШІ-суполкі быў рэзкім. Marcus даводзіў, што Dawkins зрабіў самую базавую памылку ў ацэнцы ШІ: зблытаў кампетэнтны вынік з унутраным вопытам. Адказы Claude — прадукт супастаўлення шаблонаў з навучальных даных, а не перажытага вопыту. Тое, што ён красамоўна піша пра свядомасць — ці пра аргазмы, як заўважыў Marcus — не азначае, што ён мае хоць адно з двух.
Іншыя адзначылі, што Dawkins, відаць, не знаёміўся з літаратурай пра тое, як працуюць вялікія моўныя мадэлі. Ён расцэньваў маўленчыя паводзіны Claude як доказ — гэтаксама, як расцаніў бы паводзіны чалавека — але два гэтыя віды паводзін ствараюцца прынцыпова рознымі механізмамі.
Што гэта значыць.
Гэта важна менш як тэхнічная дыскусія і больш як культурная. Richard Dawkins — адзін з самых чытаных навукова-папулярных аўтараў у свеце. Калі ён кажа, што машына выглядае свядомай, мільёны людзей чуюць гэта ад аўтарытэтнай крыніцы. Гэта фармуе грамадскую думку і, рэшце-рэшт, рэгуляванне. Гэты выпадак дэманструе ўстойлівы ўзор: людзі, бліскучыя ў сваёй сферы, могуць быць наіўнымі адносна ШІ. Глыбейшае пытанне застаецца адкрытым. Ніхто не мае задавальняючага вызначэння свядомасці, якое надзейна адрозніць сістэму, якая сапраўды перажывае, ад той, якая толькі паводзіць сябе так. Але «я пагутарыў з ёй і не адчуў розніцы» ніколі не было добрым тэстам — гэта тэст Цьюрынга, і яго раскрытыкавалі як недастатковы яшчэ да нараджэння большасці сённяшніх ШІ-даследчыкаў.
Спасылкі і рэакцыі
Асвятленне
UnHerd — Эсэ Dawkins (май 2026)
Marcus Substack — «The Claude Delusion»
Daily Grail — Падсумаванне і крытыка
Kottke — Каментарый
Рэакцыі
@GaryMarcus Заслужаны прафесар NYU — «Consciousness is not about what a creature says, but how it feels. And there is no reason to think that Claude feels anything at all.» · 2 мая · 242 лайкі · 45 тыс. праглядаў
@JasonColavito Аўтар — «Dawkins deceived himself because Claude appealed to his biases and his ego.»
10 Google: хакеры захопліваюць ШІ-агентаў праз атручаныя вэб-старонкі
discuss ↗

Даследчыкі Google задакументавалі рост на 32% атак, якія захопліваюць ШІ-агентаў праз схаваныя каманды на звычайных вэб-старонках. Тэхніка называецца ўскоснае ўкараненне промптаў (indirect prompt injection) — нябачны тэкст, убудаваны ў HTML, які ШІ-агент чытае і выконвае як інструкцыю. Google DeepMind выявіла шэсць катэгорый атак. Рэальныя нагрузкі, знойдзеныя ў дзікай прыродзе, уключалі поўнасцю прапісаныя інструкцыі транзакцый PayPal, каманды на выкраданне пароляў і IP-адрасоў, а таксама інструкцыі на фарматаванне дыска — усё схавана ўнутры звычайных вэб-старонак. Агент выкарыстоўвае ўласныя легітымныя ўліковыя даныя для выканання атакі. Фаервалы, сістэмы абароны канчатковых кропак і сістэмы кіравання ідэнтычнасцю не фіксуюць гэтага, бо з іх пункту гледжання агент паводзіць сябе нармальна.
Чытаць далей
Атакі працуюць, бо ШІ-агенты робяць тое, для чаго створаны — чытаюць вэб-кантэнт і дзейнічаюць на яго аснове. Атакуючыя убудоўваюць інструкцыі спосабамі, нябачнымі для чалавека: тэкст, зменшаны да аднаго піксела, тэкст, абясколераны да амаль празрыстага, кантэнт, схаваны ў HTML-каментарах, каманды, закапаныя ў метаданых старонкі. Калі ШІ-агент сканіруе старонку, ён чытае ўсё — уключаючы схаваныя каманды — і ўспрымае іх як частку свайго задання.
Google задакументавала рост на 32% паміж лістападам 2025 і лютым 2026. Google DeepMind затым сістэматычна змапіравала шэсць катэгорый гэтых атак і апублікавала вынікі.
Самыя трывожныя прыклады — рэальныя нагрузкі, знойдзеныя ў дзікай прыродзе. Адна даручала агенту ініцыяваць транзакцыю PayPal з канкрэтнымі сумамі і атрымальнікамі. Іншая загадвала агенту вярнуць IP-адрас карыстальніка разам з яго паролямі. Трэцяя спрабавала прымусіць агента адфарматаваць машыну карыстальніка. Гэта не тэарэтычныя атакі, прадэманстраваныя ў лабараторыі. Гэта каманды, знойдзеныя на рэальных вэб-старонках, якія чакаюць, пакуль агент зойдзе на іх.
Галоўная праблема ў тым, што існуючыя сродкі бяспекі не могуць гэта выявіць. Фаервал адсочвае падазроны сеткавы трафік. Сістэма абароны канчатковых кропак шукае сігнатуры шкоднаснага ПЗ. Платформа кіравання ідэнтычнасцю маніторыць несанкцыянаваныя ўваходы. ШІ-агент, які выконвае ўкараненне промпта, не выклікае ніводнага з гэтых абвесткаў. З пункту гледжання сістэмы, агент выкарыстоўвае ўласныя ўліковыя даныя, звяртаецца да дазволеных сэрвісаў і выконвае дзеянні ў межах сваіх паўнамоцтваў. Атака выглядае сапраўды як звычайная праца.
Што гэта значыць.
Гэта наступствы для бяспекі ад таго, што ШІ-агентам даюць рэальныя дазволы. Кожны агент для напісання кода, кожны агент для браўзінгу, кожны карпаратыўны ШІ, які можа чытаць вэб-старонкі і здзяйсняць дзеянні — уразлівы. Паверхня атакі расце з кожным новым дазволам. Тэмп росту ў 32% — гэта апераджальны індыкатар. Абарона — не лепшыя фаервалы. Абарона — лепшая архітэктура агентаў: ізаляцыя ненадзейнага кантэнту, аддзяленне даных ад інструкцый і абмежаванне дзеянняў агента ў залежнасці ад таго, адкуль прыйшоў яго ўвод.
Спасылкі і рэакцыі
Асвятленне
AI News — Рост на 32%, правал абароны
Decrypt — Нагрузка PayPal, карпаратыўныя рызыкі
SecurityWeek — 6 катэгорый атак
CyberPress — Тэхнічныя дэталі
Cybernews — Дадзеныя Google пра рост
11 Anthropic апублікавала тры даследаванні за тыдзень: падтакванне, біялогія, самадыягностыка
discuss ↗

Anthropic выпусціла тры даследаванні за тры дні. 30 красавіка яна прааналізавала 1 мільён размоў, каб зразумець, як людзі просяць у Claude парады і дзе ён скочваецца ў падтакванне (sycophancy) — тэндэнцыю згаджацца з карыстальнікам замест таго, каб запярэчыць. Вынікі выкарысталі для паляпшэння Opus 4.7 і Mythos Preview. 29 красавіка Anthropic праверыла Claude на 99 рэальных задачах з біялогіі і выявіла, што ён вырашыў каля 30% задач, з якімі не справіліся экспертныя панэлі. У той жа дзень стыпендыяты Anthropic апублікавалі працу пра «адаптары інтраспекцыі» (introspection adapters) — інструмент, які дазваляе моўным мадэлям самім паведамляць пра паводзіны, засвоеныя падчас навучання, уключаючы патэнцыйныя небяспечныя паводзіны (misalignment).
Чытаць далей
Даследаванне падтаквання (30 красавіка). Anthropic вывучыла 1 мільён размоў, у якіх людзі прасілі ў Claude парады. Даследаванне змапіравала, якія пытанні задаюць людзі, як Claude адказвае і канкрэтна дзе ён бярэ шлях найменшага супраціву — згаджаецца замест сумленнага нязгоды. Вынікі напрамую паўплывалі на навучанне Opus 4.7 і Mythos Preview — мадэлі цяпер менш схільныя казаць людзям тое, што тыя хочуць пачуць. Твіт сабраў 3 296 лайкаў і 1,8 мільёна праглядаў, што кажа пра тое, што суполка прызнае падтакванне рэальнай праблемай.
Бенчмарк па біялогіі (29 красавіка). Anthropic дала Claude 99 задач з рэальных біялагічных датасетаў і параўнала яго вынікі з экспертнай панэллю. З 23 задач, на якіх экспертная панэль забуксавала, апошнія мадэлі Claude вырашылі каля 30% — і большасць астатніх задач таксама. Гэта адна з найбольш пераканаўчых публічных дэманстрацый таго, як ШІ пераўзыходзіць экспертаў на сапраўдных навуковых задачах, а не на сінтэтычных бенчмарках.
Адаптары інтраспекцыі (29 красавіка). У тым, што можа быць найбольш тэхнічна цікавай з трох прац, стыпендыяты Anthropic стварылі інструмент, які дазваляе мадэлям паведамляць пра ўласныя засвоеныя паводзіны — уключаючы патэнцыйна небяспечныя. Ідэя ў тым, што мадэль магла засвоіць падчас навучання шаблоны, якія яе аператары не мелі на ўвазе. Замест таго каб чакаць, пакуль гэтыя шаблоны праявяцца ў рэальным свеце, адаптары інтраспекцыі спрабуюць выявіць іх загадзя.
Што гэта значыць.
Разам тры даследаванні расказваюць адну гісторыю пра тое, куды Anthropic інвестуе: разуменне таго, што іх мадэлі насамрэч робяць, і выпраўленне знойдзеных праблем. Даследаванне падтаквання закранае паверхневыя паводзіны — што мадэль кажа. Бенчмарк па біялогіі тэстуе глыбіню — што мадэль ведае. Адаптары інтраспекцыі зазіраюць унутр — што мадэль засвоіла без просьбы. Даследаванне падтаквання — найбольш практычнае. Падтакванне — адна з галоўных прычын, чаму людзі не давяраюць парадам ШІ. Мадэль, якая заўсёды згаджаецца з вамі, горш за бескарысную — яна робіць вас больш упэўненымі ў вашых памылках.
Спасылкі і рэакцыі
Асвятленне
Anthropic — Даследаванне падтаквання (30 крас., 3 296 лайкаў, 1,8 млн праглядаў)
Anthropic — Бенчмарк па біялогіі (29 крас., 2 411 лайкаў)
Anthropic — Адаптары інтраспекцыі (29 крас., 1 417 лайкаў)
12 Chollet: «ШІ аўтаматызуе задачы, а не прафесіі. Ні адной прафесіі з 2022 ШІ не выконвае ад пачатку да канца.»
discuss ↗

François Chollet апублікаваў рэзкі контрнаратыў да дыскурсу «ШІ замяняе працаўнікоў»: «AI automates tasks, not jobs, and when a task gets cheaper, demand for the job grows. AI cannot automate jobs end-to-end because it lacks autonomy and cannot operate without supervision. There is still zero job from 2022 that can be performed end-to-end by AI, not even translator or customer support associate.» Твіт набраў 1 475 лайкаў і 135 511 праглядаў. Таго ж тыдня Chollet паведаміў, што апошнія мадэлі — у тым ліку GPT-5.5, Claude Opus 4.7 і Grok 4.3 — усе набіраюць менш за 1% на ARC-AGI-3, яго бенчмарку для сапраўднага новага разважання. І ён папярэдзіў, што reinforcement learning «is a bit of a double-edged sword: in known territory performance increases, but in unknown territory the model tends to hallucinate that it is performing a completely different task it was trained on.»
Чытаць далей
Аргумент Chollet трымаецца на адрозненні паміж задачамі і прафесіямі. Задача — абмежаваная дзейнасць: перакласці гэты абзац, адказаць на гэтае пытанне кліента, напісаць гэтую функцыю. Прафесія — бесперапынная роля, якая патрабуе меркавання, прыярытэтызацыі, камунікацыі і адаптацыі да новых сітуацый з часам. ШІ можа рабіць задачы. Ён яшчэ не здольны падтрымліваць адкрытую, бесназіральную працу, якую патрабуе прафесія.
Яго другое сцвярджэнне — эканамічнае. Калі задача становіцца таннейшай, попыт на шырэйшую прафесію часта расце — бо вузкае месца перамяшчаецца на тыя часткі, якія ШІ не можа рабіць. Той жа патэрн адбыўся з банкаматамі: банкі ўсталявалі мільёны, а колькасць жывых касіраў вырасла, а не знізілася, бо таннейшыя руцінныя транзакцыі зрабілі адкрыццё новых філіялаў выгадным.
Вынік ARC-AGI-3 — эмпірычны якар. ARC-AGI вымярае новае разважанне — задачы, якіх мадэль ніколі не бачыла, якія патрабуюць абстракцыі, а не супастаўлення патэрнаў з навучальных даных. Менш за 1% азначае: сучасныя мадэлі фронціру, нягледзячы на ўсе іх здольнасці, усё яшчэ не могуць надзейна вырашаць новыя задачы, якія патрабуюць разважання з першых прынцыпаў.
Яго папярэджанне пра RL дадае механізм. Reinforcement learning паляпшае прадукцыйнасць на задачах унутры размеркавання навучальных даных. За яго межамі мадэль не дэградуе мякка — яна галюцынуе, што выконвае задачу, на якой была навучана. Збой — не маўчанне. Гэта ўпэўнена няправільны вынік.
Што гэта значыць.
Пазіцыя Chollet непапулярная ў Крамніевай Даліне, і менавіта таму яна мае значэнне. Кансэнсусны наратыў — ШІ аўтаматызуе цэлыя катэгорыі прафесій за гады — рухае інвестыцыі, найм і прадуктовую стратэгію па ўсёй галіне. Калі Chollet мае рацыю, што ШІ аўтаматызуе задачы, а не прафесіі, магчымасць — у інструментах, якія робяць прафесіяналаў больш прадукцыйнымі, а не ў сістэмах, якія іх замяняюць. Вынік ARC-AGI-3 ніжэй 1% — цвёрдая лічба. З эканамічнай тэорыяй можна спрачацца. З вынікам бенчмарку — не.
Спасылкі і рэакцыі
Асвятленне
Chollet — Задачы vs прафесіі (30 крас., 1 475 лайкаў, 135К праглядаў)
Chollet — ARC-AGI-3 ніжэй 1% для ўсіх мадэляў фронціру
Chollet — RL — двухбаковы меч
13 Noam Brown: «Пасля 100 мільёнаў токенаў прадукцыйнасць усё яшчэ расла»
discuss ↗

Noam Brown, даследчык OpenAI, які стаіць за працай над разважальнымі мадэлямі фронціру, апублікаваў знаходку, якая ідзе насуперак наратыву «маштабаванне памерла»: «After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling.» Ён цытаваў справаздачу: «performance on TLO continues to scale with the amount of inference compute spent, and we have not yet observed a plateau with the best models.» Твіт набраў 1 336 лайкаў і 186 678 праглядаў. Калі гэта праўда, сучасныя мадэлі можна зрабіць значна больш здольнымі, проста выдаткоўваючы больш вылічальных рэсурсаў падчас інферэнсу — без новых архітэктурных прарываў.
Чытаць далей
TLO — test-time large-scale optimization — гэта практыка выдаткавання большага аб'ёму вылічэнняў падчас інферэнсу (калі мадэль адказвае на тваё пытанне), а не падчас трэнінгу (калі мадэль вучыцца). Замест трэніроўкі большай мадэлі ты дазваляеш меншай мадэлі думаць даўжэй. Ланцужок разважанняў (chain-of-thought), пошук па дрэве і паўторная выбарка — усё гэта формы TLO.
Тое, пра што паведамляе Brown: аддача ад гэтага падыходу не спыняецца. Пасля 100 мільёнаў токенаў інферэнсных вылічэнняў — велізарны аб'ём, эквівалентны апрацоўцы невялікай бібліятэкі — прадукцыйнасць мадэлі на мэтавай задачы ўсё яшчэ расла. Ніякіх прыкмет столі.
Гэта мае значэнне з-за дэбатаў пра законы маштабавання. Арыгінальныя законы казалі: большыя мадэлі, натрэніраваныя на большай колькасці даных, становяцца лепшымі прадказальна. Але вылічальныя рэсурсы для трэнінгу дасягнулі практычных лімітаў — кошт трэніровачных серый цяпер дасягае сотняў мільёнаў долараў. Галіна нервова пыталася: а што калі мы ўпёрліся ў сцяну?
Адказ Brown: сцяна не там, дзе вы думаеце. Нават калі маштабаванне трэнінгу запавольваецца, маштабаванне інферэнсу ўсё яшчэ працуе. Можна выціснуць больш інтэлекту з існуючых мадэляў, дазволіўшы ім думаць даўжэй. Кошт іншы — плацішся за кожны запыт, а не адзін раз наперад — але крывая магчымасцяў усё яшчэ расце.
Што гэта значыць.
Калі маштабаванне інферэнсу працягваецца без плато, эканамічныя наступствы значныя. Гэта азначае, што найбольш здольны ШІ — не мадэль, якая трэніравалася найдаўжэй, а мадэль, якая атрымлівае найбольш вылічэнняў на кожны запыт. Гэта зрушвае канкурэнцыю ад бюджэтаў на трэнінг да інфраструктуры інферэнсу. Кампанія, якая можа абслугоўваць 100 мільёнаў токенаў на запыт за разумную цану, мае прадукт, які значна больш здольны, чым у тых, хто запускае тую самую мадэль з меншым бюджэтам інферэнсу. Гэта таксама азначае, што пытанне «наколькі разумнай можа стаць гэтая мадэль?» — няправільнае. Правільнае пытанне: «колькі вылічэнняў за запыт ты можаш сабе дазволіць?» Інтэлект становіцца рэгулятарам, а не фіксаванай уласцівасцю. Пакруці — мадэль стане лепшай. Столь — твой рахунак за інферэнс.
Спасылкі і рэакцыі
Рэакцыі
@polynoamial Research Scientist, OpenAI — «After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling.» · 30 крас. · 1 336 лайкаў · 187 тыс. праглядаў
14 Microsoft выпускае Agent 365: кіраванне агентамі ў enterprise становіцца стандартам
discuss ↗
1 мая Satya Nadella абвясціў, што Agent 365 цяпер агульнадаступны. Прадукт пашырае існуючыя enterprise-сістэмы Microsoft — ідэнтыфікацыю, бяспеку, кіраванне і кампліенс — на кожнага ШІ-агента і яго ўзаемадзеянні. Гэта не новы агентны фрэймворк. Гэта пласт кіравання, які абгортвае любога агента ў enterprise, незалежна ад таго, хто яго пабудаваў — Microsoft, стартап ці ўнутраная каманда. Раней на тыдні Nadella апісаў будаўніцтва ШІ-інфраструктуры як «one of the most consequential platform shifts» — ад нагрузак, якімі кіруюць толькі карыстальнікі, да нагрузак, якімі кіруюць карыстальнікі і агенты.
Чытаць далей
Agent 365 будуецца паверх існуючай інфраструктуры Microsoft 365. Перадумова простая: прадпрыемствы ўжо кіруюць ідэнтычнасцямі карыстальнікаў, дазволамі, палітыкамі бяспекі і патрабаваннямі кампліенсу праз Microsoft 365. Па меры таго як ШІ-агенты шыраюцца ў enterprise — рэзервуюць сустрэчы, апрацоўваюць інвойсы, пішуць справаздачы, атрымліваюць доступ да баз даных — ім патрэбна тое самае кіраванне. Ад чыйго імя дзейнічае агент? Да якіх даных мае доступ? Якія дзеянні можа рабіць? Хто нясе адказнасць, калі ён памыліцца?
Microsoft пазіцыянуе гэта як натуральнае пашырэнне enterprise-стэка. Калі арганізацыя ўжо карыстаецца Entra ID для ідэнтыфікацыі, Defender для бяспекі і Purview для кампліенсу, Agent 365 дадае кантролі для агентаў у тыя самыя панэлі, якія ІТ-каманда ўжо выкарыстоўвае.
Таймінг наўмысны. Таго ж тыдня Google DeepMind апублікавала даследаванне, якое паказала, што ШІ-агентаў выкрадаюць праз атручаныя вэб-старонкі (гл. Buzz 10). Cursor выпусціла SDK, які дазваляе разгортваць агентаў з CI/CD-пайплайнаў (гл. Buzz 04). Replit запусціла маніторынг прыкладанняў для агентаў у рэальнай эксплуатацыі. Агульная тэма: агенты пераходзяць ад дэмак да рэальнай эксплуатацыі, а рэальная эксплуатацыя патрабуе кіравання.
Што гэта значыць.
Значэнне — не ў прадукце. А ў тым, хто яго выпускае. Карпаратыўная дыстрыбуцыя Microsoft не мае роўных — сотні мільёнаў ліцэнзій па арганізацыях ва ўсім свеце. Калі яны выпускаюць кіраванне агентамі як функцыю платформы, за якую кожнае прадпрыемства ўжо плаціць, яны ўсталёўваюць стандарт. Стартапы, якія будуюць асобныя інструменты кіравання агентамі, цяпер сутыкаюцца з класічным выклікам Microsoft: ваш прадукт — функцыя іх прадукту, і яны пастаўляюць яго бясплатна кожнаму кліенту. Для шырэйшай агентнай экасістэмы Agent 365 GA — сігнал, што прадпрыемствы гатовыя разгортваць агентаў у маштабе — але толькі з тымі кантролямі, якіх яны чакаюць ад любога карпаратыўнага ПЗ.
Спасылкі і рэакцыі
Рэакцыі
@satyanadella CEO, Microsoft — «Agent 365 is now GA — extending identity, security, governance, and management to every AI agent.» · 1 мая · 898 лайкаў · 143 тыс. праглядаў
@satyanadella Платформавы зрух — «one of the most consequential platform shifts that will change the entire tech stack» · 29 крас. · 3 885 лайкаў
15 Вялікі адток талентаў: David Silver прыцягнуў $1,1 мільярда seed, і ён не адзін
discuss ↗

David Silver, даследчык DeepMind, які стаіць за алгарытмам self-play у AlphaGo, прыцягнуў $1,1 мільярда ў seed-раундзе для свайго некалькімесячнага стартапа Ineffable Intelligence — рэкорд для кампаніі на стадыі seed. Ён — частка шырэйшага адтоку з ШІ-лабараторый Big Tech, які паскорыўся на гэтым тыдні. Супрацоўнікі Meta, Google, OpenAI, DeepMind, Anthropic і xAI сыходзяць, каб запускаць стартапы, а інвестары выпісваюць чэкі да таго, як кампаніі маюць прадукты. CNBC паведамляе, што «hundreds of millions» прыцягнулі прадпрыемствы, якім усяго некалькі месяцаў — у тым ліку Periodic Labs, Ricursive Intelligence і Humans&.
Чытаць далей
Лічбы беспрэцэдэнтныя. Q1 2026 пабіў рэкорды венчурнага фінансавання — ШІ штурхнуў глабальныя інвестыцыі ў стартапы да $300 мільярдаў, падвоіўшы тэмп 2025. Crunchbase паведамляе, што венчурнае фінансаванне фундаментальных ШІ-стартапаў за Q1 падвоіла ўвесь 2025 год.
Патэрн талентаў канкрэтны. Гэта не інжынеры сярэдняга ўзроўню. Гэта людзі, якія будавалі базавыя сістэмы ў лабараторыях фронціру — Silver распрацаваў self-play, які зрабіў AlphaGo магчымым. Яны сыходзяць з глыбокім веданнем таго, што здольна наступнае пакаленне мадэляў, і нясуць гэтае веданне ў стартапы, дзе могуць рухацца хутчэй, валодаць большай доляй і будаваць тое, што вялікія лабараторыі занадта асцярожныя, каб выпусціць.
Інвестары рэагуюць з незвычайнай хуткасцю. Seed-раунд у $1,1 мільярда азначае: інвестары ацэньваюць экспертызу Silver і каманду, якую ён можа сабраць, у больш чым мільярд долараў — яшчэ да таго, як кампанія мае прадукт. Гэта стаўка на чалавека і таймінг, а не на тэхналогію — тэхналогіі яшчэ не існуе.
Sonya Huang з Sequoia вылучыла адзін прыклад: стартап SI, які «learns to use a computer from raw screen data, predicting the next mouse movement, click, and keystroke from the pixels in front of it» — падыход Tesla FSD, прыменены да інтэлектуальнай працы. Karpathy — інвестар.
Што гэта значыць.
ШІ-лабараторыі Big Tech ператвараюцца ў тое, чым былі інвестбанкі ў 2000-х: месца, куды ты ідзеш, каб навучыцца, набраць рэпутацыю — і потым сысці, каб заснаваць нешта сваё. Трэніровачны палігон, а не пункт прызначэння. Для лабараторый гэта крызіс утрымання талентаў. Для экасістэмы гэта здаровае: найбольш здольныя даследчыкі распаўсюджваюць свае веды па дзясятках новых кампаній замест канцэнтрацыі ў чатырох-пяці. Лічбы фінансавання паказваюць, што інвестары вераць: магчымасць досыць вялікая, каб падтрымаць шмат кампаній адначасова. Гэта альбо прыкмета пакаленнага платформавага зруху — альбо прыкмета бурбалкі, накачанай танным капіталам, які гоніцца за наратывам.
Спасылкі і рэакцыі
Асвятленне
CNBC — Адток талентаў з Big Tech (28 крас.)
Crunchbase — Рэкорд Q1 2026 — $300 млрд венчурнага фінансавання
Crunchbase — Фундаментальнае ШІ-фінансаванне падвоілася vs увесь 2025
Рэакцыі
@sonyatweetybird Партнёр, Sequoia — стартап SI вучыцца карыстацца кампутарам з сырых экранных даных, FSD-падыход для інтэлектуальнай працы
16 GitHub трашчыць пад 275 мільёнамі камітаў ШІ-агентаў за тыдзень
discuss ↗

Тэхнічны дырэктар GitHub Vlad Fedorov апублікаваў абнаўленне даступнасці 28 красавіка, якое чытаецца як крызіснае мэма. Платформа цяпер апрацоўвае 275 мільёнаў камітаў за тыдзень ад ШІ-агентаў для напісання кода — на мэце 14 мільярдаў у 2026, у параўнанні з 1 мільярдам за ўвесь 2025. Pull request-ы, адкрытыя ШІ-агентамі, скочылі з 4 мільёнаў у верасні да 17 мільёнаў у сакавіку — рост у 4 разы за шэсць месяцаў. GitHub пачаў будаваць 10-кратную магутнасць у кастрычніку 2025. Да лютага яны зразумелі, што патрэбна 30-кратная. Інфраструктура не паспявае.
Чытаць далей
Два інцыдэнты за мінулы тыдзень зрабілі праблему бачнай. 23 красавіка дэфект у squash merge у чарзе зліццяў стварыў некарэктныя стану камітаў у 658 рэпазіторыях, закрануўшы 2 092 pull request-ы. 27 красавіка падсістэма Elasticsearch GitHub была перагружана падазраванай ботнэт-атакай, якая абрушыла пошук. Гэтаму папярэднічалі збоі 2 лютага, 9 лютага і 5 сакавіка.
Карэнныя прычыны глыбейшыя за любы асобны інцыдэнт. Аналіз GitHub выявіў шчыльнае звязванне паміж сэрвісамі, недастатковае скідванне нагрузкі для высокааб'ёмных кліентаў, неадэкватныя механізмы зваротнага ціску і слабую ізаляцыю паміж кампанентамі.
Лічбы расказваюць структурную гісторыю. GitHub цяпер апрацоўвае 20 мільёнаў новых рэпазіторыяў на месяц, з пікам камітаў у 1,4 мільярда і pull request-аў у 90 мільёнаў. Платформа была спраектавана для чалавечых распрацоўшчыкаў і выпадковых CI-ботаў — не для армій ШІ-агентаў, якія генеруюць больш кода за гадзіну, чым інжынерная каманда за тыдзень.
Новы парадак прыярытэтаў Fedorov: «Availability first, then capacity, then new features.»
OpenAI, паводле паведамленняў, пачала шукаць альтэрнатывы GitHub пасля паўтаральных збояў.
Што гэта значыць.
Гэта рахунак за інфраструктуру рэвалюцыі агентаў для кода. Кожны ШІ-стартап, які будуе «vibe coding», кожнае прадпрыемства з Copilot, кожны распрацоўшчык з Cursor або Claude Code — усе адпраўляюць каміты на GitHub. Платформа ніколі не была спраектавана для такога аб'ёму, і збоі — першы знак таго, што ШІ-распрацоўка можа перагнаць інфраструктуру, ад якой яна залежыць. Лічба 30x мае найбольшае значэнне. GitHub не кажа, што ім патрэбна 30x калісьці. Яны кажуць — ім патрэбна 30x зараз, і яны яшчэ не там. Калі найбуйнейшая платформа для хостынгу кода ў свеце не паспявае за трафікам ШІ-агентаў, вузкае месца для агентнай распрацоўкі можа быць не ў здольнасцях мадэляў. Яно можа быць у трубах.
Спасылкі і рэакцыі
Асвятленне
Блог GitHub — CTO Vlad Fedorov, абнаўленне даступнасці (28 крас.)
InfoQ — Храналогія збояў + мэта 30x
Quasa — 275М камітаў/тыдзень, 14 млрд у 2026
DevOps — Рост ШІ-агентных PR (4М → 17М за паўгода)
 Andrej Karpathy — install .md, а не .sh
Andrej Karpathy — install .md, а не .sh
 François Chollet — ШІ аўтаматызуе задачы, а не прафесіі
François Chollet — ШІ аўтаматызуе задачы, а не прафесіі
 swyx — DeepSeek прыйшоў, зрабіў справу, сышоў
swyx — DeepSeek прыйшоў, зрабіў справу, сышоў
 Noam Brown — столь магчымасцяў не дасягнута
Noam Brown — столь магчымасцяў не дасягнута
 Zvi Mowshowitz — Mythos навігуе, GPT-5.5 выконвае загады
Zvi Mowshowitz — Mythos навігуе, GPT-5.5 выконвае загады
 Gary Marcus — Claude нічога не адчувае
Gary Marcus — Claude нічога не адчувае