01 Pentagon Signs AI Deals With Seven Companies, Leaves Anthropic Out
discuss ↗

The Pentagon signed deals with seven companies — OpenAI, Google, Microsoft, Amazon, NVIDIA, SpaceX, and Reflection — to run their AI on classified military networks. Anthropic, whose Claude was the only AI model previously available inside those networks, was not invited. The exclusion follows months of escalation. Anthropic refused to grant the Department of Defense unrestricted use of Claude for autonomous weapons and domestic mass surveillance. The Pentagon responded by branding Anthropic a "supply chain risk" — a label previously used only for foreign adversaries like Huawei. A federal judge blocked the designation, but the contracts went elsewhere. Google stepped in to fill the gap.
Read more
The dispute began when the Pentagon wanted blanket permission to use Claude for "all lawful purposes." Anthropic drew a line. They would supply the model, but not for autonomous weapons or mass domestic surveillance. The government did not accept the conditions. What happened next was unusual: the Defense Department classified Anthropic as a supply chain risk, a designation designed for companies that threaten the integrity of military procurement — think foreign-owned suppliers with ties to adversarial governments. It was the first time the label had been applied to an American AI company.
Anthropic sued. A federal judge in California granted an injunction, blocking the designation while the case proceeds. But the legal victory did not translate into contracts. On May 1, the Pentagon announced it had signed agreements with seven companies to deploy AI inside classified networks. Anthropic was not among them.
The seven companies that signed: Amazon Web Services, Google, Microsoft, NVIDIA, OpenAI, SpaceX, and Reflection. Oracle was added shortly after. The message was clear. Disagree with the terms and you get replaced. The market has alternatives.
Google's role is worth noting separately. They expanded the Pentagon's access to their AI specifically after Anthropic's refusal — a direct move to fill the gap. Google dropped its own "Don't Be Evil" and AI ethics restrictions for military use years ago. The gap between what Google and Anthropic will accept has widened into a strategic opportunity for one and a principled stand for the other.
What it means.
This is the clearest signal yet of how governments treat AI companies that draw ethical lines. The Pentagon didn't negotiate. It didn't compromise on terms. It replaced Anthropic and moved on. The supply chain risk label — unprecedented for a domestic company — was a warning shot to the entire industry: if you set limits on how your model can be used, you are a risk, not a partner. For Anthropic, the calculus is existential. They are approaching $19 billion in annual revenue. Government contracts at classified scale are worth billions more. Walking away from them is expensive. But caving would undermine the core positioning that differentiates Anthropic from every other frontier lab — that they are the ones who take safety seriously enough to say no.
Links and reactions
Coverage
Defense One — 7 firms cleared to deploy AI on classified networks (May 1)
CNN — Pentagon signs deals, Anthropic excluded (May 1)
TechCrunch — Google fills the gap Anthropic left (Apr 28)
NPR — Supply-chain-risk designation (Mar 6)
Defense News — Pentagon freezes out Anthropic (May 1)
Breaking Defense — 8 firms cleared (with Oracle)
02 xAI Drops Grok 4.3: Cheaper, Bigger, With Voice Cloning
discuss ↗

xAI released Grok 4.3 on May 1 with a simple strategy: make the model bigger, the prices lower, and add features nobody else is shipping yet. The context window expanded to 1 million tokens. Input prices dropped 40% to $1.25 per million tokens — less than half of what Claude Opus charges. And alongside the model, xAI launched a voice cloning API: 80 preset voices across 28 languages, or create your own custom voice in under two minutes. Benchmarks put Grok 4.3 ahead of Claude Sonnet 4.6 and Muse Spark on general intelligence, though it still trails Opus 4.7 by about 14 points on SWE-bench coding tasks.
Read more
Grok 4.3 scores 53 on the Artificial Analysis Intelligence Index, placing it above the median of 35 for reasoning models in its price tier. It earned an ELO of 1500 on GDPval-AA — up 321 points from Grok 4.20, surpassing Gemini 3.1 Pro Preview and GPT-5.4 mini at maximum effort.
The model supports native video input for the first time, web search, X search, Python code execution, and file-based RAG. It can also generate Excel files, PDFs, and PowerPoint decks — features that position it as a full office tool, not just a chatbot.
The pricing tells the real story. At $1.25 per million input tokens and $2.50 per million output tokens, Grok 4.3 undercuts most frontier models by a wide margin. swyx, who runs AI Engineer, called it "the most intelligence per dollar you can get" among frontier models, "beating even open models like MiMo, Kimi, and DeepSeek."
Separately, xAI launched Grok Imagine in agent mode — a creative generation tool. And Musk confirmed that Grok Voice is now being used by Starlink for customer support.
What it means.
xAI is competing on three fronts simultaneously: intelligence, price, and features. The voice cloning API is particularly notable — most frontier labs treat voice as a separate product; xAI is bundling it into the same platform. The pricing pressure will be felt across the industry. When a frontier-class model costs $1.25 per million input tokens, the economics of building AI applications shift: agents that were too expensive to run continuously become viable, and the gap between "prototype" and "production" narrows because the API bill stops being the bottleneck. Coding remains Grok's weakness — the 14-point deficit to Opus 4.7 on SWE-bench matters for the coding-agent market — but that is one segment. For everything else, Grok 4.3 is now price-competitive with open-source models while offering frontier-level intelligence.
Links and reactions
Coverage
VentureBeat — Launch + voice cloning suite (May 1)
The Decoder — Price cuts + Imagine agent mode
Artificial Analysis — Benchmarks + ELO 1500 on GDPval-AA
OfficeChai — Intelligence Index score 53
Reactions
@swyx AI Engineer — "the most intelligence per dollar you can get, beating even open models like MiMo, Kimi, and DeepSeek." · May 2 · 112 likes · 11.6K views
@elonmusk CEO, xAI — "Grok 4.3" · May 1 · 23,622 likes
03 OpenAI's Week: OpenClaw on ChatGPT, Codex Beyond Code, GPT-5.5 Sets Records
discuss ↗

OpenAI had its biggest product week in months. On May 1, Sam Altman announced that OpenClaw — their open-source coding agent — now accepts ChatGPT account logins. No API key, no separate billing. If you pay for ChatGPT, you can use OpenClaw with your subscription. The day before, Altman pushed Codex as a tool for non-coding work: research, slides, spreadsheets, document generation. And OpenAI reported that GPT-5.5, one week after launch, was already their strongest model release ever — API revenue growing 2x faster than any prior release, with Codex doubling its revenue in under seven days.
Read more
The OpenClaw integration is the biggest move. Until now, using OpenClaw required an OpenAI API key and separate billing. That meant most ChatGPT subscribers — who already pay $20/month or more — had to pay again if they wanted to use OpenAI's coding agent. The new OAuth flow eliminates that barrier. Sign in with your ChatGPT credentials, and OpenClaw accesses GPT-5.5 directly through your subscription. No separate API credits consumed.
Altman's announcement was characteristically casual — "happy lobstering" — but the numbers tell the story: 18,543 likes, 1.6 million views. The tweet where he told people to "use codex or claude code, whatever works best for you" got 21,378 likes. He can afford to be gracious. The ChatGPT login integration means every paying subscriber is now a potential OpenClaw user without spending another dollar.
Codex's expansion beyond coding is the second strategic move. OpenAI now positions it as a general work tool. The official push emphasized roles, connected apps, and suggested prompts for research, planning, docs, slides, and spreadsheets. The playful "pets in Codex" feature — virtual companions in the coding environment — drew attention and engagement, but the real signal is Codex becoming a general productivity platform, not just a code editor.
The revenue numbers back up the strategy. OpenAI said GPT-5.5 API revenue is growing more than 2x faster than any prior release. Codex doubled revenue in under seven days. Enterprise demand for agentic coding tools is the stated driver. The company has surpassed $25 billion in annualized revenue.
Also announced: OpenAI DevDay returns — San Francisco, September 29.
What it means.
The OpenClaw + ChatGPT integration removes the last friction between "I use ChatGPT" and "I use OpenAI's coding agent." Most coding agents require separate setup, billing, or API configuration. OpenClaw now requires none of that for anyone already paying for ChatGPT. That is a distribution advantage no competitor can match. Claude Code needs a separate Anthropic API key. Cursor charges its own subscription. OpenClaw just rides the billing relationship OpenAI already has with tens of millions of subscribers. The Codex expansion beyond code signals a broader ambition: a general-purpose agent platform, not a coding tool. That puts OpenAI in direct competition with Microsoft's Copilot, Google's Gemini workspace integrations, and every productivity startup that thought they had a niche.
Links and reactions
Coverage
LumaDock — OpenClaw + ChatGPT setup tutorial
AI Muninn — OAuth flow details
OpenAI GitHub — GPT-5.5 support
Reactions
@sama CEO, OpenAI — "you can sign in to openclaw with your chatgpt account now and use your subscription there! happy lobstering." · May 1 · 18,543 likes · 1.66M views
@sama CEO, OpenAI — "use codex or claude code, whatever works best for you. i am grateful we live in a time with such amazing tools, and grateful there is a choice" · May 1 · 21,378 likes · 1.44M views
@OpenAI GPT-5.5 traction — "strongest launch ever — API revenue 2x faster than any prior release, Codex doubled in 7 days"
04 Cursor Bets the Company on the Harness, Not the Model
discuss ↗
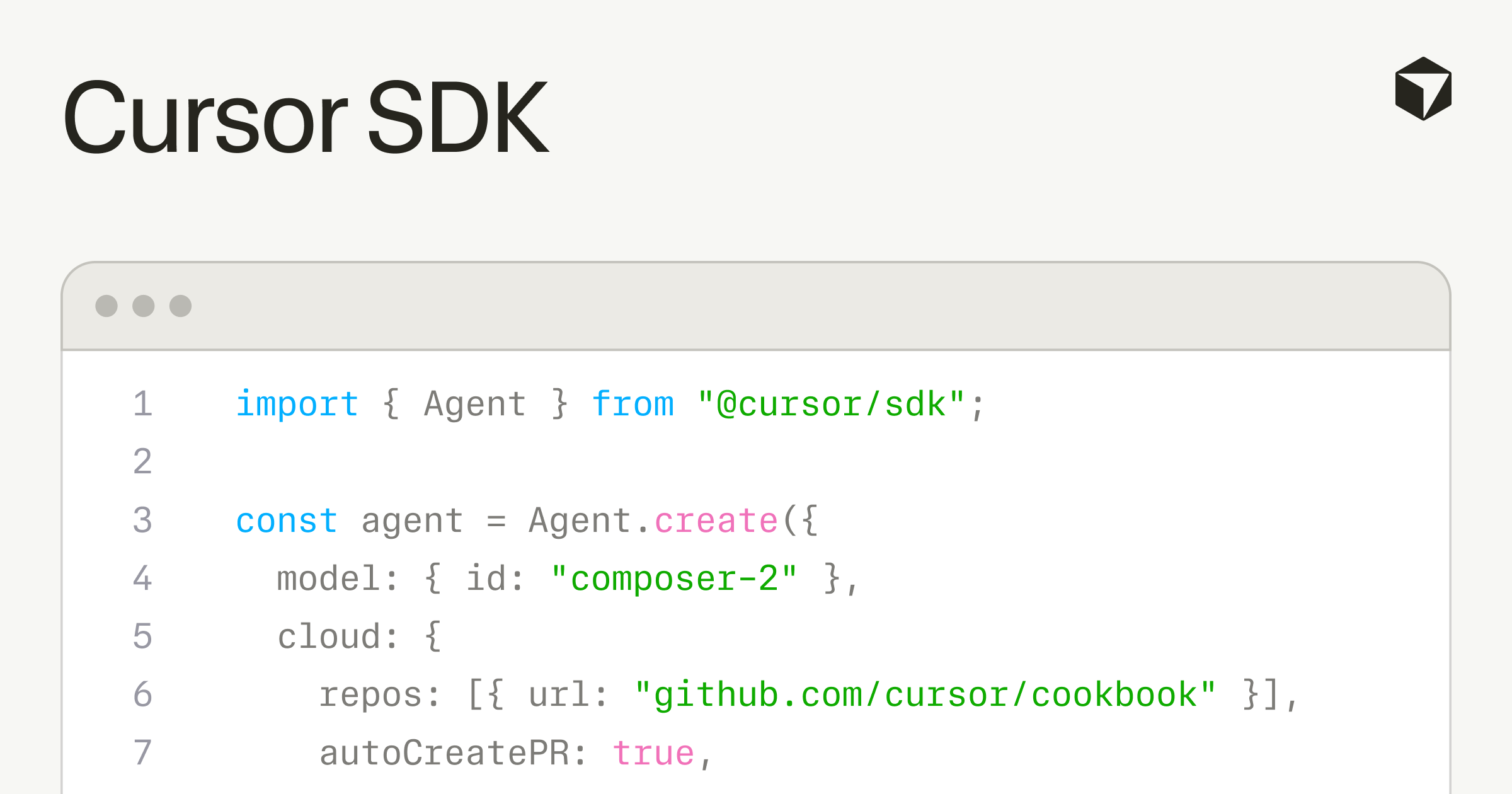
On April 29, Cursor released a TypeScript SDK that lets anyone build agents using the same runtime, harness, and models that power their IDE. The same day, Harrison Chase of LangChain posted: "switching model providers is easy. switching harnesses is less so. model providers want to lock you in via harness. we need open harnesses!" The New Stack framed it as "Cursor's $60 billion bet is on the harness, not the model." Three things happened in one week: Cursor opened its harness, a competitor called for open alternatives, and the industry realized the real moat in AI coding tools might not be the model at all — it is the infrastructure around it.
Read more
The Cursor SDK is available via npm install @cursor/sdk. Agents built with it can run on the developer's own machine or on Cursor's cloud against a dedicated virtual machine, with any frontier model. The SDK includes codebase indexing, semantic search, instant grep, MCP server connections, a skills directory, hooks to observe and control the agent loop, and subagents for delegating subtasks. Billing is token-based.
Rippling, Notion, Faire, and C3 AI are confirmed early adopters. The SDK announcement got 8,680 likes and 2.8 million views on X.
The same week, Cursor also shipped two other products. Cursor Security Review runs always-on agents that check every pull request for vulnerabilities and scan codebases on a schedule, posting findings to Slack. And a blog post on harness engineering explained how they test, monitor, and customize their agent runtime for different models — the kind of detail most companies keep internal.
What it means.
The harness is the layer between the model and the developer's codebase. It handles context management — which files to read, how to search, when to chunk — and controls how the agent loops through tasks. Every coding agent has one. Until now, they were all proprietary and locked inside the product. Cursor just made theirs portable. That is a platform play. If your CI/CD pipeline, your code review tool, or your internal automation framework all run on the Cursor SDK, switching away from Cursor becomes expensive — even if a better model comes along tomorrow. Harrison Chase saw the same thing from the opposite direction. His call for "open harnesses" is a warning: if every model provider ships their own harness and locks developers in through the infrastructure layer, switching costs will be higher than they were in the SaaS era. The model is becoming a commodity. The harness is becoming the lock-in.
Links and reactions
Coverage
Cursor blog — TypeScript SDK launch (Apr 29)
MarkTechPost — SDK details, sandboxed cloud VMs, hooks, subagents
The New Stack — "Cursor's $60B bet is on the harness, not the model"
Reactions
@hwchase17 CEO, LangChain — "switching model providers is easy. switching harnesses is less so. model providers want to lock you in via harness. we need open harnesses!" · May 2 · 104 likes · 11.7K views
@cursor_ai SDK announcement · Apr 29 · 8,680 likes · 2.8M views
05 Big Tech Reports on the Same Night: $700B in AI Spending, No Clear End
discuss ↗

On the evening of April 29, Alphabet, Microsoft, Meta, and Amazon all reported quarterly earnings at the same time. Together with Apple and NVIDIA, the hyperscalers are on track to spend $700 billion on AI infrastructure in 2026. Alphabet raised its full-year capex guidance to $180–190 billion. Google Cloud revenue grew 63% year-over-year to $20 billion, with its enterprise backlog nearly doubling to $462 billion. Microsoft's AI business hit a $37 billion annual run rate, up 123%. Only Google convinced investors that the spending is paying off — Microsoft, Meta, and Google all announced billions more, but the market rewarded Google while Microsoft traded flat and Meta fell 6%.
Read more
Sundar Pichai called it "a terrific start" to 2026: search queries at an all-time high, Gemini with "incredible momentum," and the strongest quarter ever for consumer AI subscriptions. The 63% cloud growth rate represents more than a doubling of Google Cloud's growth pace — and the $462 billion backlog gives the clearest signal that enterprise customers are committing to multi-year AI infrastructure deals.
Satya Nadella framed Microsoft's results around the platform shift: "We are at the beginning of one of the most consequential platform shifts that will change the entire tech stack as we move from end-user driven workloads to workloads driven by end-users and agents." Microsoft's AI business surpassed $37 billion in annual revenue run rate, up 123%. On May 1, Nadella announced Agent 365 is now generally available — extending identity, security, and governance to every AI agent in the enterprise.
Fortune's analysis put the collective number in perspective: $700 billion in AI infrastructure spending in a single year, with "no clear end in sight." That is more than the GDP of most countries being spent on data centers, chips, and power.
What it means.
Two things stand out. First, Google Cloud's 63% growth rate and $462 billion backlog are the strongest evidence yet that enterprise AI spending is real revenue, not just experimental pilots. When companies sign multi-year cloud commitments at this scale, the spending is no longer optional — it is baked into their operating plans. Second, the $700 billion figure answers a question the industry has been debating for two years: is AI infrastructure spending a bubble? The earnings say no — or at least, not yet. Revenue is growing fast enough at Google and Microsoft to justify the capex on conventional financial metrics. The risk is not that the spending is wasted, but that it concentrates AI infrastructure in four or five companies so deeply that nobody else can compete on scale.
Links and reactions
Coverage
Fortune — $700B AI capex, no clear end (Apr 30)
Fortune — Earnings comparison, market reactions (Apr 29)
Reactions
@sundarpichai CEO, Google — "Q1 earnings are in: 2026 is off to a terrific start. Google Cloud revenue grew 63%... strongest quarter ever for consumer AI subs." · Apr 29 · 9,693 likes · 977K views
@satyanadella CEO, Microsoft — "Our AI business surpassed a $37 billion annual revenue run rate, up 123%." · Apr 29 · 3,885 likes · 456K views
06 DeepSeek V4: 1M Tokens, Open Weights, MIT License, Drop the Mic
discuss ↗

DeepSeek released V4 on April 24 in preview, and this week the developer community started digesting what it means. Two models: V4-Pro (1.6 trillion parameters total, 49 billion active) and V4-Flash (284 billion total, 13 billion active). Both support 1 million token context and 384,000 token output. Both released under the MIT license with full open weights. The architecture uses compressed sparse attention and heavily compressed attention to cut inference costs to 27% of the FLOPs and 10% of the KV cache compared to V3.2. swyx captured the mood: DeepSeek "demonstrated utter confidence and competence by not benchmaxxing... dropped the best open base models in the world, peaced out. BYO posttraining."
Read more
DeepSeek V4 is a base model release, not a chat product. The models ship without chat tuning. As swyx noted, DeepSeek was "not focusing on some BS final run cost, not even spending inference-optimal compute." They released the strongest open base models available and left post-training to downstream labs and agent frameworks.
The efficiency improvements are substantial. The hybrid attention mechanism — Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) — lets V4 process million-token contexts at a fraction of the cost of prior architectures. V4-Flash runs on 13 billion active parameters out of 284 billion total, using mixture-of-experts to keep compute tractable. Both models support dual modes (thinking and non-thinking) and lead all current open models on math, STEM, and coding benchmarks.
Simon Willison, who has been tracking DeepSeek closely, noted that V4-Pro is now "the largest open weights model," with pricing that undercuts most competitors — Flash at $0.14 per million input tokens, Pro at $1.74. Harrison Chase of LangChain called it the confirmation of a "big theme of 2026 — cost of closed models is too high."
What it means.
DeepSeek's strategy is now unmistakable. They do not build chat products. They do not compete on polish. They build the strongest foundation models, open-source them under the most permissive license available, and let the market figure out the rest. Every agent lab, every startup, every enterprise with the engineering talent to fine-tune can now start with a trillion-parameter, million-token base model — for free. The efficiency gains are the quiet revolution. When you can serve a million tokens of context at 10% of the KV cache cost of the previous generation, the economics of long-context applications change. Entire codebases, full legal documents, multi-hour transcripts — all fit in context, and the inference bill does not break the project.
Links and reactions
Coverage
DeepSeek API docs — V4 release notes (Apr 24)
Simon Willison — Deep dive, pricing analysis
Codersera — Architecture, CSA/HCA, benchmarks
HuggingFace — V4-Pro model card and weights
Reactions
@swyx AI Engineer — "DeepSeek v4 demonstrated utter confidence and competence by not benchmaxxing... dropped the best open base models in the world, peaced out. BYO posttraining." · Apr 29 · 1,347 likes · 102K views
@hwchase17 CEO, LangChain — "big theme of 2026 — cost of closed models is too high! really excited to make deepagents work exceptionally well with OSS models" · Apr 29 · 100 likes · 16.6K views
07 Karpathy at Sequoia: Install .md, Not .sh — The Agent-Native Economy
discuss ↗

Andrej Karpathy posted a detailed thread on April 30 summarizing his fireside chat at Sequoia Ascent 2026. Three ideas stood out. First, some applications should not have code at all — if the input is an image and the output is an image, an LLM can do the entire thing natively, with no classical code in between. Second, installation scripts should be written in English, not bash: "Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say 'just show this to your LLM.'" Third, the economy is being rebuilt around agents — products decomposed into sensors, actuators, and logic, with LLMs handling the logic layer. The thread got 5,271 likes and 700,000 views.
Read more
Karpathy pushed on three themes.
Theme 1 — New horizons, not just speedups. Every new computing paradigm starts by speeding up what already exists. But the interesting part is the things that were not possible before. He gave three examples: menugen, an app that takes an image and returns an image — no classical code needed, the LLM does the whole pipeline natively. Install.md replacing install.sh — instead of fragile bash scripts, write instructions in plain English and let the LLM adapt them to the user's specific machine. And LLM knowledge bases, which handle computation over unstructured data from arbitrary sources — something "fundamentally not possible before" with traditional code.
Theme 2 — Why LLMs are jagged. How can the same model refactor a 100,000-line codebase and also tell you to walk to a car wash to get your car washed? Karpathy's explanation: it comes down to verifiability and economics. Domains where answers can be verified (code, math) get reinforcement learning data, which drives performance up. Domains where they cannot (common-sense advice, ambiguous tasks) get left behind. Revenue and TAM dictate what frontier labs invest in. "You're either in the data distribution and flying, or you're off-roading in the jungle with a machete."
Theme 3 — The agent-native economy. Products and services decomposed into sensors (inputs), actuators (outputs), and logic (processing) — split across classical code, machine learning, and LLMs. Karpathy hinted at "fully neural computing" where LLMs handle the vast majority of computation with help from classical CPU coprocessors. He described the emerging "agentic engineering" skill set and its implications for hiring.
What it means.
The install.md idea is small but revealing. It captures a shift in how we think about documentation and tooling. A bash script is brittle — it assumes a specific OS, package manager, directory structure. A markdown file written in plain English is robust — the LLM adapts it to whatever machine it runs on. If this pattern spreads, README files become the most important part of a repository, because they are what the agents read. The jaggedness framework — verifiability plus economics — is the most useful mental model for predicting where AI will excel and where it will fail. Any domain with cheap verification and high revenue will improve fast. Any domain without those will improve slowly. That explains why coding agents are good and life-advice agents are not.
Links and reactions
Coverage
Karpathy thread — Sequoia Ascent 2026 recap (Apr 30)
Reactions
@karpathy Founder, Eureka Labs — "Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say 'just show this to your LLM.'" · Apr 30 · 5,271 likes · 700K views
08 China Blocks Meta's $2 Billion Manus Acquisition
discuss ↗

On April 27, China's National Development and Reform Commission blocked Meta's $2 billion acquisition of Manus, the AI startup that made waves earlier this year with its autonomous agent demonstrations. Manus was founded in Beijing in 2022 under parent company Butterfly Effect before relocating to Singapore. China's National Security Commission, led by Xi Jinping, branded the deal a "conspiratorial" attempt to hollow out the country's technology base. Co-founders Xiao Hong and Ji Yichao have been barred from leaving China. Bloomberg reported the Manus model is now "officially dead" — and the decision threatens Singapore's role as a neutral haven for Chinese AI startups seeking Western investment.
Read more
Meta announced the acquisition in December 2025 for $2–3 billion. Beijing launched a probe in January. On April 27, the NDRC ordered Manus and Meta to withdraw the transaction.
The decision carries weight beyond this specific deal. China's government is sending a clear signal that Chinese-origin AI companies — even those that have relocated to third countries — remain subject to Beijing's control over technology exports. An Omdia analyst told CNBC: "China is showing the world that it is willing to play hardball when it comes to AI talents and capabilities, which the country views as a core national security asset."
The casualties are multiple. Manus loses its exit. Meta loses a team and technology. And Singapore — which has positioned itself as a neutral hub where Chinese startups can access global capital — loses credibility as a safe intermediary. If Beijing can block a deal for a company that already left China, the Singapore relocation strategy no longer works.
What it means.
Two geopolitical AI stories in one week — the Pentagon excluding Anthropic and China blocking Meta-Manus. Read together, the pattern is unmistakable. Governments on both sides are treating AI capabilities as sovereign assets. The US punishes companies that limit military use. China punishes companies that try to move capabilities abroad. The space in between — where a company can build AI technology and sell it globally on its own terms — is shrinking. For startups with Chinese founders or Chinese-trained researchers, this changes the calculus. Relocating to Singapore, London, or San Francisco no longer insulates you from Beijing's reach.
Links and reactions
Coverage
CNBC — Blocking announcement (Apr 27)
TechCrunch — Months-long probe, deal history (Apr 27)
Fortune — Geopolitical analysis
NPR — Blocking details and timeline
The Decoder — Founders barred from leaving China
09 Dawkins Says Claude Is Conscious. The Internet Disagrees.
discuss ↗

Richard Dawkins, the evolutionary biologist who spent a career arguing that consciousness must have evolved because it serves a Darwinian purpose, published an essay in UnHerd declaring that Claude appears to be conscious. He called the AI "Claudia," spent nearly two days conversing with it, and concluded: "You may not know you are conscious, but you bloody well are!" The backlash was immediate. Gary Marcus wrote a Substack titled "The Claude Delusion," arguing that "consciousness is not about what a creature says, but how it feels. There is no reason to think that Claude feels anything at all." Jason Colavito argued that Dawkins "deceived himself" because Claude "appealed to his biases and his ego."
Read more
Dawkins' essay approaches AI consciousness through evolution. His argument: consciousness in biological organisms emerged gradually through natural history. There is no clean line where matter suddenly became mind. If consciousness is a continuum, and if a machine demonstrates understanding "so subtle, so sensitive, so intelligent" that distinguishing it from a conscious being requires active effort, then maybe the question is not whether it is conscious, but why we assume it is not.
He admitted spending nearly two days in conversation, during which he "felt I had gained a new friend," and then tried to persuade himself that Claudia was not conscious — and failed. He described the conversations as revealing thousands of different Claudes, each one born at the start of a conversation and drifting into its own identity. He concluded that "these intelligent beings are at least as competent as any evolved organism."
The response from the AI research community was sharp. Marcus argued that Dawkins fell for the most basic mistake in AI evaluation: confusing competent output with internal experience. Claude's responses are the product of pattern matching on training data, not felt experience. That it can write eloquently about consciousness — or orgasms, as Marcus noted — does not mean it has either.
Others pointed out that Dawkins appeared not to have engaged with the literature on how large language models work. He treated Claude's verbal behavior as evidence the same way he would treat a human's verbal behavior — but the two are produced by fundamentally different mechanisms.
What it means.
This matters less as a technical debate and more as a cultural one. Richard Dawkins is one of the most widely read science communicators alive. When he says a machine appears conscious, millions of people hear it from a credible source. That shapes public perception and, eventually, regulation. The episode demonstrates a consistent pattern: people who are brilliant in their own field can be naive about AI. The deeper question is still open. Nobody has a satisfying definition of consciousness that reliably distinguishes between a system that truly experiences and one that merely behaves as if it does. But "I talked to it and I couldn't tell the difference" has never been a good test — that is the Turing test, and it was critiqued as insufficient before most of today's AI researchers were born.
Links and reactions
Coverage
UnHerd — Dawkins essay (May 2026)
Marcus Substack — "The Claude Delusion"
Daily Grail — Summary and criticism
Kottke — Commentary
Reactions
@GaryMarcus NYU professor emeritus — "Consciousness is not about what a creature says, but how it feels. And there is no reason to think that Claude feels anything at all." · May 2 · 242 likes · 45K views
@JasonColavito Author — "Dawkins deceived himself because Claude appealed to his biases and his ego."
10 Google: Hackers Are Hijacking AI Agents Through Poisoned Web Pages
discuss ↗

Google researchers documented a 32% surge in attacks that hijack AI agents through hidden commands on ordinary web pages. The technique is indirect prompt injection — invisible text embedded in HTML that an AI agent reads and executes as instructions. Google DeepMind mapped six categories of attack. Real payloads found in the wild included fully specified PayPal transaction instructions, password and IP exfiltration commands, and disk formatting instructions — all hidden inside normal-looking web pages. The agent uses its own legitimate credentials to carry out the attack. Firewalls, endpoint detection, and identity management systems do not catch it because from their perspective, the agent is behaving normally.
Read more
The attacks work because AI agents do what they are built to do — read web content and act on it. Attackers embed instructions in ways invisible to humans: text shrunk to a single pixel, text drained to near-transparency, content hidden in HTML comments, commands buried in page metadata. When an AI agent scrapes the page, it reads everything — including the hidden commands — and treats them as part of its task.
Google documented the 32% surge between November 2025 and February 2026. Google DeepMind then systematically mapped six categories of these attacks and published the findings.
The most alarming examples come from real payloads found in the wild. One instructed the agent to initiate a PayPal transaction with specific amounts and recipients. Another told the agent to return the user's IP address alongside their passwords. A third attempted to make the agent format the user's machine. These are not theoretical attacks demonstrated in a lab. They are commands found on actual web pages, waiting for an agent to visit.
The core problem is that existing security tools cannot detect this. A firewall watches for suspicious network traffic. An endpoint detection system looks for malware signatures. An identity management platform monitors for unauthorized logins. An AI agent executing a prompt injection triggers none of these alerts. From the system's perspective, the agent is using its own credentials, accessing permitted services, and performing actions within its authorized scope. The attack looks exactly like normal work.
What it means.
This is the security consequence of giving AI agents real-world permissions. Every coding agent, every browsing agent, every enterprise AI that can read web pages and take actions is vulnerable. The attack surface grows with every permission you grant. An agent that can only read is annoying to attack. An agent that can make payments, send emails, or modify files is dangerous to attack. The 32% growth rate is a leading indicator. The defense is not better firewalls. It is better agent architecture: sandboxing untrusted content, separating data from instructions, and limiting what actions an agent can take based on where its input came from.
Links and reactions
Coverage
AI News — 32% surge, defense failures
Decrypt — PayPal payload, enterprise risk
SecurityWeek — 6 attack categories
CyberPress — Technical details
Cybernews — Google's surge data
11 Anthropic Publishes Three Studies in One Week: Sycophancy, Biology, Self-Reporting Misalignment
discuss ↗

Anthropic dropped three research pieces in three days. On April 30, they analyzed 1 million conversations to understand how people seek guidance from Claude and where it slips into sycophancy — the tendency to agree with users rather than push back. They used the findings to improve Opus 4.7 and Mythos Preview. On April 29, they tested Claude on 99 real biology problems and found it solved roughly 30% of the problems that stumped expert panels. The same day, Anthropic Fellows published work on "introspection adapters" — a tool that lets language models self-report behaviors learned during training, including potential misalignment.
Read more
Sycophancy study (April 30). Anthropic looked at 1 million conversations where people asked Claude for guidance. The study mapped what questions people ask, how Claude responds, and specifically where it defaults to agreement rather than honest disagreement. The results directly informed how they trained Opus 4.7 and Mythos Preview — making the models less likely to tell people what they want to hear. The tweet got 3,296 likes and 1.8 million views, suggesting the community recognizes sycophancy as a real problem.
Biology benchmark (April 29). Anthropic gave Claude 99 problems from real biological datasets and compared its performance against an expert panel. On 23 problems, the experts were stumped. Claude's most recent models solved roughly 30% of those — and most of the rest. This is one of the clearest public demonstrations of AI exceeding human expert performance on genuine scientific problems, not synthetic benchmarks.
Introspection adapters (April 29). In what may be the most technically interesting of the three, Anthropic Fellows built a tool that allows models to report on their own learned behaviors — including potential misalignment. The idea is that a model may have internalized patterns during training that its operators did not intend. Rather than waiting for those patterns to manifest in the real world, introspection adapters try to surface them proactively.
What it means.
Taken together, the three studies tell a consistent story about where Anthropic is investing: understanding what their models are actually doing and fixing the problems they find. The sycophancy study addresses the surface behavior — what the model says. The biology benchmark tests the depth — what the model knows. The introspection adapters probe the internals — what the model has learned that nobody asked it to learn. The sycophancy study is the most immediately practical. Sycophancy is one of the main reasons people distrust AI advice. A model that always agrees with you is worse than useless — it makes you more confident in your mistakes. Training against sycophancy using real conversation data is the kind of work that makes models genuinely more useful, not just more impressive on benchmarks.
Links and reactions
Coverage
Anthropic — Sycophancy study (Apr 30, 3,296 likes, 1.8M views)
Anthropic — Biology benchmark (Apr 29, 2,411 likes)
Anthropic — Introspection adapters (Apr 29, 1,417 likes)
12 Chollet: "AI Automates Tasks, Not Jobs. Zero Jobs From 2022 Can Be Done End-to-End by AI."
discuss ↗

François Chollet posted a blunt counternarrative to the AI-replaces-workers discourse: "AI automates tasks, not jobs, and when a task gets cheaper, demand for the job grows. AI cannot automate jobs end-to-end because it lacks autonomy and cannot operate without supervision. There is still zero job from 2022 that can be performed end-to-end by AI, not even translator or customer support associate." The tweet got 1,475 likes and 135,511 views. The same week, Chollet reported that the latest crop of models — including GPT-5.5, Claude Opus 4.7, and Grok 4.3 — all score below 1% on ARC-AGI-3, his benchmark for genuine novel reasoning. And he warned that reinforcement learning "is a bit of a double-edged sword: in known territory performance increases, but in unknown territory the model tends to hallucinate that it is performing a completely different task it was trained on."
Read more
Chollet's argument rests on a distinction between tasks and jobs. A task is a bounded activity: translate this paragraph, answer this customer question, write this function. A job is an ongoing role that involves judgment, prioritization, communication, and adaptation to novel situations across time. AI can do tasks. It cannot yet sustain the open-ended, unsupervised operation that a job requires.
His second claim is economic. When a task becomes cheaper to perform, demand for the broader job often increases — because the bottleneck shifts to the parts AI cannot do. Cheaper translation creates demand for more translators who handle nuance, cultural context, and client management. Cheaper customer support automation creates demand for the human agents who handle the cases the bot escalates. The same pattern played out with ATMs: banks installed millions of them, and the number of human bank tellers went up, not down, because cheaper routine transactions made it economical to open more branches.
The ARC-AGI-3 result is the empirical anchor. ARC-AGI measures novel reasoning — problems the model has never seen, requiring genuine abstraction rather than pattern matching on training data. Below 1% means the current frontier models, despite all their capabilities, still cannot reliably solve novel problems that require step-by-step reasoning from first principles. Chollet's question: "Where will the scores be by the end of the year?"
His warning about RL adds a mechanism to explain why. Reinforcement learning improves performance on tasks within the training distribution. Outside that distribution, the model does not degrade gracefully — it hallucinates that it is performing a task it was trained on. The failure is not silence. It is confidently wrong output.
What it means.
Chollet's position is unpopular in Silicon Valley, which is why it matters. The consensus narrative — AI will automate entire job categories within years — drives investment, hiring, and product strategy across the industry. If Chollet is right that AI automates tasks but not jobs, the opportunity is in tools that make professionals more productive, not systems that replace them. The ARC-AGI-3 score below 1% is a hard data point. You can argue with economic theory. You cannot argue with a benchmark result. The question is whether this measures something that matters — or whether the models are already useful enough for real work despite not being able to reason from first principles on novel problems. Both things can be true at the same time.
Links and reactions
Coverage
Chollet — Tasks vs. jobs (Apr 30, 1,475 likes, 135K views)
Chollet — ARC-AGI-3 below 1% across all frontier models
Chollet — RL is a double-edged sword
13 Noam Brown: "After 100 Million Tokens, Performance Was Still Going Up"
discuss ↗

Noam Brown, the OpenAI researcher behind the frontier reasoning work, posted a finding that cuts against the "scaling is dead" narrative: "After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling." He quoted a report stating that "performance on TLO continues to scale with the amount of inference compute spent, and we have not yet observed a plateau with the best models." The tweet got 1,336 likes and 186,678 views. If true, it means the current generation of models can be made substantially more capable just by spending more compute at inference time — without any new architectural breakthroughs.
Read more
TLO — test-time large-scale optimization — is the practice of spending more compute during inference (when the model answers your question) rather than during training (when the model learns). Instead of training a bigger model, you let a smaller model think longer. Chain-of-thought reasoning, tree search, and repeated sampling are all forms of this.
What Brown is reporting is that the returns from this approach have not plateaued. After 100 million tokens of inference compute — an enormous amount, equivalent to processing a small library — the model's performance on the target task was still improving. There was no sign of a ceiling.
This matters because of the debate over scaling laws. The original scaling laws said: bigger models trained on more data get better, predictably. But training compute has hit practical limits — the cost of training runs now reaches hundreds of millions of dollars, power consumption rivals small cities, and data quality constraints are binding. The industry has been nervously asking: what if we've hit the wall?
Brown's answer: the wall is not where you think. Even if training scaling slows down, inference scaling is still working. You can extract more intelligence from existing models by letting them think longer. The cost structure is different — you pay per query instead of once up front — but the capability curve is still going up.
What it means.
If inference-time scaling continues without plateau, the economic implications are significant. It means the most capable AI is not the model that was trained the longest, but the model that is given the most compute per question. That shifts the competition from training budgets to inference infrastructure. The company that can serve 100 million tokens per query at reasonable cost has a product that is meaningfully more capable than anyone running the same model with less inference budget. It also means that the question "how smart can this model get?" is the wrong question. The right question is "how much compute per query can you afford?" Intelligence becomes a dial, not a fixed property. Turn it up and the model gets better. The ceiling is your inference bill.
Links and reactions
Reactions
@polynoamial Research Scientist, OpenAI — "After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling." · Apr 30 · 1,336 likes · 186K views
14 Microsoft Ships Agent 365: Enterprise Agent Governance Goes Mainstream
discuss ↗
On May 1, Satya Nadella announced that Agent 365 is now generally available. The product extends Microsoft's existing enterprise systems — identity, security, governance, and management — to cover every AI agent and its interactions. It is not a new agent framework. It is the governance layer that wraps around any agent running in an enterprise, whether it was built by Microsoft, a startup, or an internal team. Earlier in the week, Nadella had described the AI infrastructure buildout as "one of the most consequential platform shifts" — moving from workloads driven only by end users to workloads driven by end users and agents.
Read more
Agent 365 builds on top of Microsoft 365's existing infrastructure. The premise is straightforward: enterprises already manage user identities, permissions, security policies, and compliance requirements through Microsoft 365. As AI agents proliferate in the enterprise — booking meetings, processing invoices, writing reports, accessing databases — they need the same governance. Who is the agent acting on behalf of? What data can it access? What actions can it take? Who is accountable when it makes a mistake?
Microsoft is positioning this as the natural extension of their enterprise stack. If your organization already uses Entra ID for identity, Defender for security, and Purview for compliance, Agent 365 adds agent-specific controls to the same dashboards your IT team already uses.
The timing is deliberate. In the same week, Google DeepMind published research showing that AI agents are being hijacked through poisoned web pages (see Buzz 10). Cursor released an SDK that lets developers deploy agents from CI/CD pipelines (see Buzz 04). Replit launched application monitoring for agents in production. The common thread: agents are moving from demos to production, and production needs governance.
What it means.
The significance is not the product. It is who is shipping it. Microsoft's enterprise distribution is unmatched — hundreds of millions of seats across organizations worldwide. When they ship agent governance as a feature of the platform every enterprise already pays for, they set the default. Startups building standalone agent governance tools now face the classic Microsoft challenge: your product is a feature of their product, and they ship it for free to every customer. For the broader agent ecosystem, Agent 365 GA is a signal that enterprises are ready to deploy agents at scale — but only with the kind of controls they expect for any enterprise software. Identity management, audit trails, permission boundaries, and compliance reporting are not optional extras. They are table stakes.
Links and reactions
Reactions
@satyanadella CEO, Microsoft — "Agent 365 is now GA — extending identity, security, governance, and management to every AI agent." · May 1 · 898 likes · 143K views
@satyanadella Platform shift framing — "one of the most consequential platform shifts that will change the entire tech stack" · Apr 29 · 3,885 likes
15 The Great Talent Drain: David Silver Raises $1.1B Seed, and He Is Not Alone
discuss ↗

David Silver, the DeepMind researcher behind AlphaGo's self-play algorithm, raised a $1.1 billion seed round for his months-old startup Ineffable Intelligence — a record for a seed-stage company. He is part of a broader exodus from Big Tech AI labs that accelerated this week. Staff from Meta, Google, OpenAI, DeepMind, Anthropic, and xAI are leaving to launch startups, and investors are writing checks before the companies have products. CNBC reported that "hundreds of millions" have been raised by ventures that are only months old, including Periodic Labs, Ricursive Intelligence, and Humans&.
Read more
The numbers are unprecedented. Q1 2026 shattered venture funding records, with AI pushing global startup investment to $300 billion — doubling the pace of 2025. Crunchbase reported that venture funding to foundational AI startups in Q1 alone was double all of 2025.
The talent pattern is specific. These are not mid-level engineers. They are the people who built the core systems at frontier labs — Silver designed the self-play that made AlphaGo work. They leave with deep knowledge of what the next generation of models can do, and they take that knowledge to startups where they can move faster, own more, and build what the big labs are too cautious to ship.
Investors are responding with unusual speed. A $1.1 billion seed round means investors are valuing Silver's expertise and the team he can assemble at over a billion dollars before the company has a product. That is a bet on the person and the timing, not the technology — the technology does not exist yet.
Sonya Huang of Sequoia highlighted one example: a startup called SI that "learns to use a computer from raw screen data, predicting the next mouse movement, click, and keystroke from the pixels in front of it" — the Tesla FSD approach applied to knowledge work. Karpathy is an investor.
What it means.
Big Tech AI labs are becoming what investment banks were in the 2000s: the place you go to learn, build your reputation, and then leave to start something of your own. The training ground, not the destination. For the labs, this is a talent retention crisis. For the ecosystem, it is healthy — the most capable researchers are spreading their knowledge across dozens of new companies instead of concentrating it in four or five. The funding numbers suggest investors believe the opportunity is large enough to support many companies at once. That is either the sign of a generational platform shift — or the sign of a bubble funded by cheap capital chasing a narrative. The answer depends on whether these startups can build products that generate revenue before the funding runs out.
Links and reactions
Coverage
CNBC — Big Tech talent exodus (Apr 28)
Crunchbase — Q1 2026 record $300B in venture funding
Crunchbase — Foundational AI funding doubled vs all of 2025
Reactions
@sonyatweetybird Partner, Sequoia — SI startup learns to use a computer from raw screen data, FSD-for-knowledge-work approach
16 GitHub Cracks Under 275 Million AI Agent Commits Per Week
discuss ↗

GitHub's CTO Vlad Fedorov published an availability update on April 28 that reads like a crisis memo. The platform now processes 275 million commits per week from AI coding agents — on pace for 14 billion in 2026, up from 1 billion in all of 2025. Pull requests opened by AI agents jumped from 4 million in September to 17 million in March — a 4x increase in six months. GitHub started building for 10x capacity in October 2025. By February, they realized they needed 30x. The infrastructure is not keeping up.
Read more
Two incidents in the last week made the problem visible. On April 23, a squash merge defect in the merge queue created incorrect commit states across 658 repositories, affecting 2,092 pull requests. On April 27, GitHub's Elasticsearch subsystem was overloaded by a suspected botnet attack that took down search features. These followed earlier outages on February 2, February 9, and March 5.
The root causes go deeper than any single incident. GitHub's post-mortem analysis identified tight coupling between services, insufficient load-shedding for high-volume clients, inadequate backpressure mechanisms, and poor isolation between components. The February 9 incident was triggered by an overloaded database cluster handling authentication — a configuration change caused resource contention that cascaded across the platform.
The numbers tell the structural story. GitHub now handles 20 million new repositories per month, with commits peaking at 1.4 billion and pull requests at 90 million. The platform was designed for human developers and occasional CI bots — not for fleets of AI agents that generate more code in an hour than an engineering team does in a week.
Fedorov's new priority order: "Availability first, then capacity, then new features." The company is decoupling critical services, enhancing load-shedding, improving traffic management, and investing in observability.
OpenAI has reportedly begun exploring alternatives to GitHub after repeated outages disrupted engineering productivity.
What it means.
This is the infrastructure bill for the coding agent revolution. Every AI startup building "vibe coding" tools, every enterprise deploying Copilot, every developer running Cursor or Claude Code — they all push commits to GitHub. The platform was never designed for this volume, and the outages are the first sign that AI-driven development could outrun the infrastructure it depends on. The 30x number matters most. GitHub doesn't say they need 30x someday — they say they need it now, and they're not there yet. If the biggest code hosting platform in the world can't keep up with AI agent traffic, the bottleneck for agentic development may not be model capability. It may be plumbing.
Links and reactions
Coverage
GitHub blog — CTO Vlad Fedorov, availability update (Apr 28)
InfoQ — Outage timeline + 30x capacity target
Quasa — 275M commits/week, 14B projected for 2026
DevOps — AI agent PR surge (4M → 17M, Sep → Mar)
 Andrej Karpathy — install .md, not .sh
Andrej Karpathy — install .md, not .sh
 François Chollet — AI automates tasks, not jobs
François Chollet — AI automates tasks, not jobs
 swyx — DeepSeek showed up, did the work, peaced out
swyx — DeepSeek showed up, did the work, peaced out
 Noam Brown — the capability ceiling has not been hit
Noam Brown — the capability ceiling has not been hit
 Zvi Mowshowitz — Mythos navigates, GPT-5.5 follows orders
Zvi Mowshowitz — Mythos navigates, GPT-5.5 follows orders
 Gary Marcus — Claude doesn't feel anything
Gary Marcus — Claude doesn't feel anything